





Abstract
As one of the four major Chinese carps of important economic value, the grass carp (Ctenopharyngodon idellus) has attracted increasing attention from the scientific community. Recently, the draft genome has been released as a milestone in research of grass carp. In order to facilitate the utilization of these genome data, we developed the grass carp genome database (GCGD). GCGD provides visual presentation of the grass carp genome along with annotations and amino acid sequences of predicted protein-coding genes. Other related genetic and genomic data available in this database include the genetic linkage maps, microsatellite genetic markers (i.e. Short Sequence Repeats, SSRs), and some selected transcriptomic datasets. A series of tools have been integrated into GCGD for visualization, analysis and retrieval of data, e.g. JBrowse for navigation of genome annotations, BLAST for sequence alignment, EC2KEGG for comparison of metabolic pathways, IDConvert for conversion of terms across databases and ReadContigs for extraction of sequences from the grass carp genome.
Database URL:http://bioinfo.ihb.ac.cn/gcgd
Introduction
As the only species of the genus Ctenopharyngodon, the family Cyprinidae, the grass carp (Ctenopharyngodon idellus) is a herbivorous freshwater fish distributed across a wide native range from the catchment area of the Pearl River in southern China to the Heilongjiang River in northeastern China (1). Since 1960 s, grass carp has been deliberately introduced into >100 countries for aquaculture and vegetation control purposes (2). Well-known as one of the four major Chinese carps, it is the species of fish with the largest production in aquaculture globally, accounting for 15.6% of global freshwater aquaculture production in 2011 (3).
The grass carp has been well studied on many macroscopic aspects: cultivation, artificial reproduction, feeding and nutrition, disease prevention and control and even aquatic weed control (4). However, research at the molecular level has been confined only to genes involved in the immune response system (5, 6), nutrition and growth (7, 8) and control of food intake (9, 10). Very little is known about the underlying molecular mechanisms of key physiological behaviors that could have economic significance. Such mechanisms might determine the long sexual maturity period of the grass carp, which extends up to 5 years and its capability to absorb nutrients from oligotrophic weeds. Usually such complex traits are determined by multiple genes in an interaction network, requiring to be investigated at the whole-genome scale.
With the rapid development of sequencing technology, the genomes of an increasing number of teleosts have been sequenced including zebrafish (11), common carp (12), medaka (13), rainbow trout (14), Atlantic salmon (15) and large yellow croaker (16) from the Sciaenidae family. Correspondingly, web-based databases for visualization and utilization of these genomes have been developed. Well-known databases include ZFIN (17, 18) for zebrafish, CarpBase (http://www.carpbase.org) for common carp, SalmonBase (http://salmobase.org) for the Atlantic salmon and SalmonDB for salmonids species (19).
The draft genome of the grass carp was completed in 2015 by Wang et al. (20). Based on this draft genome, in-depth investigations were conducted on the evolution, vegetarian adaptation, sex determination and sex differentiation of the grass carp. Undoubtedly, it is also valuable for identification of genes related to important economic traits and for selection of new varieties with advantageous traits. In brief, whole-genome sequencing opened a new era for molecular breeding of grass carp.
In order to facilitate the utilization of the draft genome and other omics data associated with the grass carp, we present the Grass Carp Genome Database (GCGD) with a web interface which allows researchers to search or to analyze genomic and transcriptomic data. GCGD comprises the genomic sequences, the genetic linkage maps, the microsatellite markers (i.e. Simple Sequence Repeats, SSR), three transcriptomic datasets and the functional annotations of 32 811 predicted protein-coding genes. The functional annotations come from successful mapping to other public databases or terms including Gene Ontology (GO), Enzyme Commission (EC) number, KEGG Orthology (KO), KEGG pathway map, etc. A series of tools have been embedded in GCGD to improve the visualization or to provide other practical functions, as examples, JBrowse (21) for browse of genomic data, BLAST (22) for sequence similarity alignment, EC2KEGG (23) for metabolic pathway comparison between two species, IDConvert for ID conversion across databases and ReadContigs for sequence extraction from the genome. As a scalable and flexible database, the genome annotations in GCGD will be constantly updated. Furthermore, other data, including multi-omics datasets, single-nucleotide polymorphisms (SNPs) and genome-scale metabolic networks, are supposed to be introduced into the database gradually in the future.
Data analysis and preparation
Gene nomenclature
Following the 27 263 genes originally reported (20), 5548 additional genes have been predicted by the authors (unpublished), so the total gene number reaches 32 811. To name these predicted protein-coding genes of grass carp, all predicted protein sequences were aligned with sequences in Swiss-Prot and ZFIN database using BLASTP by a threshold of e < 1e-6 and score > 100. For each alignment, corresponding gene in GCGD was named as the aligned protein in Swiss-Prot or ZFIN. For example, the gene ID ‘CI_GC_3021’ was named ‘cyclin-G2 [Danio rerio]’. Other genes failed in aligning were uniformly named as the prefix ‘_PREDICTED:gene:’ followed by their locations on the draft genome. For example, the gene with ID ‘CI_GC_80’ is named as ‘_PREDICTED:gene:CI01000000_02237986_02243555’. A total of 28 771 out of 32 811 predicted protein-coding genes have been named as their counterparts in Swiss-Prot or ZFIN (Table 1).
Summary of the functional annotations of 32 811 predicted protein-coding genes
| Annotation type | No. of genes |
|---|---|
| Swiss-Prot or ZFIN | 28 771 |
| Protein term/ID | 32 811 |
| GO (Gene Ontology terms) | 19 144 |
| KO (KEGG orthology) | 5632 |
| EC (Enzyme commission number) | 4312 |
| KEGG pathways | 5632 |
| Gene family (TreeFam) | 23 842 |
| Collinear gene with zebrafish | 21 392 |
| Single-copy orthologous genes with zebrafish | 11 404 |
| Annotation type | No. of genes |
|---|---|
| Swiss-Prot or ZFIN | 28 771 |
| Protein term/ID | 32 811 |
| GO (Gene Ontology terms) | 19 144 |
| KO (KEGG orthology) | 5632 |
| EC (Enzyme commission number) | 4312 |
| KEGG pathways | 5632 |
| Gene family (TreeFam) | 23 842 |
| Collinear gene with zebrafish | 21 392 |
| Single-copy orthologous genes with zebrafish | 11 404 |
Summary of the functional annotations of 32 811 predicted protein-coding genes
| Annotation type | No. of genes |
|---|---|
| Swiss-Prot or ZFIN | 28 771 |
| Protein term/ID | 32 811 |
| GO (Gene Ontology terms) | 19 144 |
| KO (KEGG orthology) | 5632 |
| EC (Enzyme commission number) | 4312 |
| KEGG pathways | 5632 |
| Gene family (TreeFam) | 23 842 |
| Collinear gene with zebrafish | 21 392 |
| Single-copy orthologous genes with zebrafish | 11 404 |
| Annotation type | No. of genes |
|---|---|
| Swiss-Prot or ZFIN | 28 771 |
| Protein term/ID | 32 811 |
| GO (Gene Ontology terms) | 19 144 |
| KO (KEGG orthology) | 5632 |
| EC (Enzyme commission number) | 4312 |
| KEGG pathways | 5632 |
| Gene family (TreeFam) | 23 842 |
| Collinear gene with zebrafish | 21 392 |
| Single-copy orthologous genes with zebrafish | 11 404 |
Gene collinearity and genetic linkage map
The gene collinearity between the grass carp and the zebrafish (Danio rerio, genome version Zv9) was analyzed by Wang (20), and Circos (version 0.68-1) (24) was used to visualize it. The zebrafish genome is composed of 25 pairs of chromosomes (11) and the grass carp has 24 pairs. However, the draft genome of the grass carp has not yet been assembled to the level of chromosomes, and consequently the top 40 of 164 386 scaffolds, which covered the most number of collinear genes with zebrafish, were selected for this visualization. Based on a previously published linkage map of the grass carp (25), a consensus linkage map was reproduced for searching and browsing in GCGD. Marker names and genetic distances of 16 SNPs and 263 SSRs were collected and mapped to 24 linkage groups (LGs) using MapChart (26).
Functional annotations
To obtain the functional annotations of 32 811 predicted protein-coding genes, we applied a series of software tools and databases including BLASTP, Blast2GO (27), Gene Ontology (28), KEGG (29), BRENDA (30). The annotations were listed as name/alias, GO, KO, KEGG pathway map and EC number, etc. (Table 1). >20 000 genes were clustered into gene families by Treefam (31) (P < le-10 and score > = 100). Based on a list of EC numbers, 130 KEGG pathway maps were found by a comparative analysis with EC2KEGG. These maps could display the distinctions of metabolic pathways between the grass carp and the zebrafish.
SSRs
An in-house python script was used for genome-wide scanning, identifying >6 947 000 SSRs. The microsatellites were counted based on the number of nucleotides per repeat: mononucleotide (6 866 782, 94.33%), dinucleotide (309 157, 4.25%), trinucleotide (42 533, 0.73%), tetranucleotide (53 499, 0.58%), pentanucleotide (7355, 0.1%) and hexanucleotide (468, 0.01%) (Figure 1A). To facilitate retrieval from the database, SSRs were classified into two types based on their locations: the type I SSRs are located in genes and the type II SSRs are found in intergenic regions. The type I and type II account for 39.9% and 60.1% of the total SSRs, respectively, (Figure 1B). Depending upon the arrangement of nucleotides within the repeat motifs, four categories of SSRs can be defined (32, 33) (Figure 1C): (1) simple perfect SSRs (SP) with continuous repetitive units, e.g. (ATC)n; (2) simple imperfect SSRs (SIP) with one or more interruptions in the run of repeats, e.g. (ATC)mTT(ATC)n; (3) compound perfect SSRs (CP), typically, a mixture of SP SSRs, e.g. (AC)m(AGAC)n; (4) compound imperfect SSRs or interrupted CPs (CIP), a combination of compound and imperfect SSRs, e.g. (ATC)mTTG(AT)kGC(AT)n.
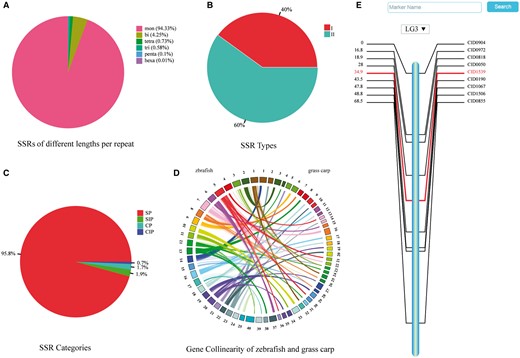
Summaries of SSRs, gene collinearity map, and a consensus linkage map. (A) Percentage of SSRs of various lengths per repeat. (B) Percentage of two types of SSRs. (C) Percentage of four categories of SSRs. (D) Gene collinearity between zebrafish and grass carp. Colored arcs connect homologous genes in zebrafish (left) and grass carp (right). (E) Genetic map of the third linkage group.
Genome sequences and transcriptomic data
Wang et al. (20) provided the complete genome sequences of a female and a male grass carp. Three transcriptomic datasets were downloaded from the NCBI Sequence Read Archive (SRA) (34) (accession numbers: SRA099702, SRP041652 and SRP055685). The datasets in SRA format were converted to FASTQ format using the NCBI SRA Toolkit, then Q20 standard was applied to eliminate low-quality reads with a Perl script (IlluQC.pl) from NGSQCToolkit (35). The filtered transcriptomic reads were aligned against the grass carp genome using Burrows-Wheeler Aligner (BWA) (36) and were finally presented in JBrowse.
Database features and utilizations
GCGD was constructed using the popular LAMP framework (Linux CentOS Server 7.1.1503, Apache 2.4.6, MySQL 5.5, and PHP 5.4.16). HTML5, CSS3 and JQuery were employed to optimize user experience. The website (http://bioinfo.ihb.ac.cn/gcgd) is supported by all major browsers. This database provides users with the facility to explore information such as genome annotation, gene function, transcriptome data and SSRs. All these data can be downloaded.
Gene collinearity
Both the grass carp and the zebrafish belong to the family Cyprinidae, and they share 11 404 single-copy orthologous genes. Such a connection is presented in the ‘Gene Collinearity’ page. Considering that the assembly of the grass carp genome is still at a ‘draft’ stage and there are no counterparts for the 25 chromosomes of zebrafish, we picked up 40 scaffolds with most genes shared with zebrafish to illustrate their gene collinearity (Figure 1D). All collinear genes can be listed in a table by clicking on a chromosome or a scaffold.
Gene family
A single gene might be duplicated to form a gene family on the genome. Generally genes within a gene family have similar biochemical functions, so researchers could save a lot of time in exploring a gene's function if they knew which gene family the gene belongs to. As described above, searching a gene results in a number of information including which gene family it belongs to. The ‘Gene Family’ page allows the user to browse all gene members for any gene family.
Genetic map
The linkage maps are essential for mapping traits of interest and understanding genome evolution of the grass carp as a diploid species (2n = 48). All the 24 linkage groups of grass carp are displayed on the ‘Genetic Map’ page as an overview. Clicking on the chart of any specific linkage group brings a map in SVG (Scalable Vector Graphics) format with a vertical bar in the middle and marker names/genetic distance on either side (Figure 1E). The details of each marker can be shown by clicking on its name or genetic distance. A pull-down option frame is provided for switching among all the linkage groups.
Gene search
Genes can be searched simply by a keyword, gene name, EC number, or various other terms (Figure 2A). The ‘advanced’ hyperlink switches to a new searching page, in which predicted protein-coding genes can be screened by more criteria and by more gene annotations including EC terms, GO terms, KEGG terms, gene family information, collinear gene information (Figure 2B). Genes are displayed in a tabular form with fields including gene ID, gene name, scaffold and location (Figure 2C). If the ‘+’ icon in front of the gene ID is clicked on, more details are visible in an expanded space below the line (Figure 2C). Generally the details cover gene ID/name/alias, gene type, protein term, gene family, collinear genes with zebrafish, GO term, EC number, KEGG term, nearby markers, nucleic acid sequence and amino acid sequence.
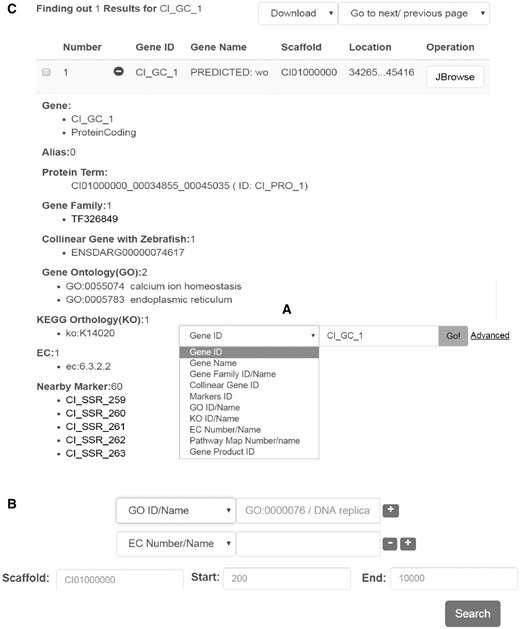
Interface for gene search and display. Data search can be performed in two different ways: (A) by keyword or under, (B) advanced search. (C) Example of the output generated upon looking for a particular gene. The results are displayed in a table format including the gene name/alias, location, sequences, and other functional features.
Genome visualization
When a search is performed, the resulting table contains a ‘JBrowse’ button which can be clicked to bring the user to an interactive genome browser (Figure 3). Biological features and dataset tracks are vertically listed on the left panel with check buttons for users to select. All checked features will be dynamically shown in JBrowse's main window. As an example, the detailed gene information only appears after clicking on the gene structure.
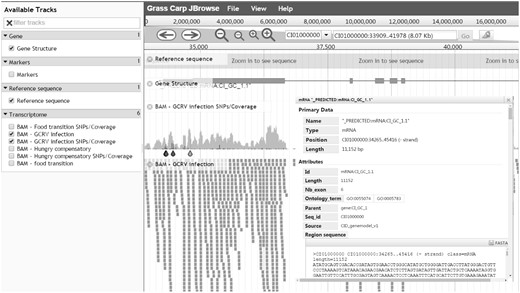
Genome visualization - JBrowse interface for navigation of genome annotations. All available data are displayed in the left frame for selection and selected data are graphically shown on the right frame. Details of a predicted protein-coding gene can be visualized after clicking on the gene.
SSR database
SSRs are often referred to as microsatellites. Because of their advantages in the feature of codominance, high polymorphism and high repeatability, SSRs are broadly utilized for species or variety identification (37), DNA fingerprint profile identification (38), gene mapping and gene locating (39), linkage map construction (25) and molecular marker assisted breeding (36, 40). This database provides access to > 349 000 SSRs identified from the grass carp genome. The overall proportions of different types of SSR are shown as pie charts in the ‘Data statistics’ page. SSRs can be searched simply by a SSR term (Figure 4A), or any combination of these terms (Figure 4B). Search results are presented in tabular form (Figure 4C).
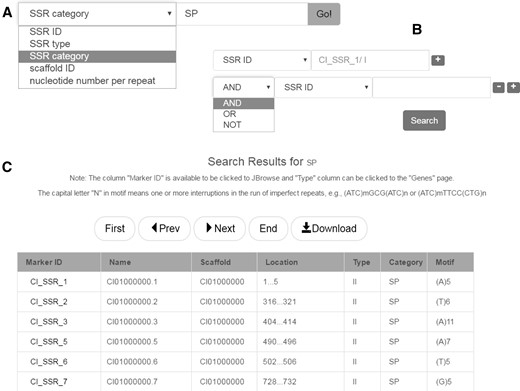
SSR database search. (A) Keyword search. (B) Advanced search. (C) The result of SSR database search.
Utilities for data mining
The NCBI Basic Local Alignment Search Tool (BLAST) program was integrated into GCGD web interface to allow users to facilitate sequence similarity search in grass carp and zebrafish. The operations include setting parameters and uploading query sequences in FASTA format, which can be pasted in a text box or be uploaded as a local file.
To assist the use of data, GCGD provided three other tools: IDConvert for term conversion, EC2KEGG for comparison of metabolic pathways and ReadContigs for sequence extraction. The disunity of terms in popular public databases hinders data exchange to a great extent, IDConvert enables the conversion of gene/protein IDs across GCGD and other databases including NCBI, Ensembl, ZFIN and Uniprot/Swiss-Prot. EC2KEGG is integrated for comparison of metabolic pathways between the grass carp and some other fishes or human. With a list of gene/protein IDs or EC numbers, EC2KEGG outputs the differences in every KEGG pathway map between the grass carp and the selected reference species. ReadContigs helps users to read segments from the draft genome of grass carp. With scaffold/contig names and sequence location information, requested sequences could be extracted and returned quickly.
Summary and future development
Owing to the limited genetic and genomic data currently available, GCGD focuses on genome annotations, the visualization of omics data and the integration of tools for data mining. As a non-model fish, grass carp is far from being sufficiently studied on its functional genomics, and most annotations in GCGD were predicted by mapping with public databases. With the aid of a set of pipelines specially developed, the associations between GCGD terms and other databases were created. These associations can be conveniently updated as the field of the grass carp genomics develops or in relation to future databases of interest.
The long sexual maturity period of grass carp poses a huge challenge for traditional approaches for variety breeding, therefore molecular assisted breeding becomes inevitable. Currently, we integrated a database for microsatellites (SSRs), the widely used molecular markers in aquatic breeding. With increasing individual genomes sequenced, a SNP database within the framework of GCGD would be desirable, providing the most accurate information of these markers in the genome.
GCGD is expected to be a comprehensive resource hub and a workbench for genomics research in the grass carp, therefore continuous efforts are indispensable to expand data coverage, to add new content to data analysis, and to improve user experience. We are constantly collecting published omics data on the grass carp for GCGD. Oncoming datasets cover genome-wide investigations on DNA methylation, genome resequencing, various additional transcriptomes and lncRNA annotation. Meanwhile, novel tools under development are for GO/KEGG enrichment, variant calling, differential expression analysis and lncRNA prediction.
The gradation of a genome assembly may be accompanied by a number of changes in gene annotations. Since we are using a draft genome at this stage, caution is advised when using this database. According to our plan, each version of genome assembly will be coupled with a new version of GCGD, while the old versions will continue being accessible. This strategy is meaningful for those who want to generate analyses comparable to previous studies. Other features including the user interface are also subject to modification based on users' feedback.
Acknowledgement
We are indebted to Dr. Jose M. Ranz (Department of Ecology and Evolutionary Biology, University of California, Irvine, CA 92697) for his suggestions on content of the manuscript and the language proofreading.
Funding
This work was supported by the Strategic Priority Research Program of the Chinese Academy of Sciences (Grant No. XDA08020201), the National High-Technology Research and Development Program (863 Program, Grant No. 2011AA100403), the National Natural Science Foundation of China (Grant No. 31571275), and the 100-talent Program, the Chinese Academy of Sciences (Grant No. Y22302).
Conflict of interest. None declared.
References
Author notes
Chen,Y., Shi,M., Zhang,W. et al. The Grass Carp Genome Database (GCGD): an online platform for genome features and annotations. Database (2017) Vol. 2017: article ID bax051; doi:10.1093/database/bax051

{kind=link}
{kind=link}
{kind=link}
{kind=link}