





Abstract
As one of the US Department of Agriculture—Agricultural Research Service flagship databases, GrainGenes (https://wheat.pw.usda.gov) serves the data and community needs of globally distributed small grains researchers for the genetic improvement of the Triticeae family and Avena species that include wheat, barley, rye and oat. GrainGenes accomplishes its mission by continually enriching its cross-linked data content following the findable, accessible, interoperable and reusable principles, enhancing and maintaining an intuitive web interface, creating tools to enable easy data access and establishing data connections within and between GrainGenes and other biological databases to facilitate knowledge discovery. GrainGenes operates within the biological database community, collaborates with curators and genome sequencing groups and contributes to the AgBioData Consortium and the International Wheat Initiative through the Wheat Information System (WheatIS). Interactive and linked content is paramount for successful biological databases and GrainGenes now has 2917 manually curated gene records, including 289 genes and 254 alleles from the Wheat Gene Catalogue (WGC). There are >4.8 million gene models in 51 genome browser assemblies, 6273 quantitative trait loci and >1.4 million genetic loci on 4756 genetic and physical maps contained within 443 mapping sets, complete with standardized metadata. Most notably, 50 new genome browsers that include outputs from the Wheat and Barley PanGenome projects have been created. We provide an example of an expression quantitative trait loci track on the International Wheat Genome Sequencing Consortium Chinese Spring wheat browser to demonstrate how genome browser tracks can be adapted for different data types. To help users benefit more from its data, GrainGenes created four tutorials available on YouTube. GrainGenes is executing its vision of service by continuously responding to the needs of the global small grains community by creating a centralized, long-term, interconnected data repository. Database URL:https://wheat.pw.usda.gov
Introduction
Large scientific datasets are being created worldwide at an unprecedented rate, volume and degree of complexity. To advance biology, these large datasets have been generated using next-generation sequencers accompanied by automated processing steps that shear large DNA chromosomes into short fragments, ligate the fragments into vectors, immobilize the fragments onto a surface, amplify the DNA by polymerase chain reaction (PCR), detect signals and interpret the data. These datasets, usually called ‘raw’ as they are not yet computationally assembled into long pseudomolecules, are required by scientific journals and funding agencies to be deposited in large archival public repositories such as GenBank (1) and the European Nucleotide Archive (ENA) (2), depending on the data types (e.g. sequencing outputs and ‘reads’ go to ENA).
After the assembly step usually come the annotation steps, where gene model positions and other genomic features (including regulatory control elements) are predicted using sophisticated algorithms, such as machine learning, that combine available data and heuristic approaches. The data are then analyzed to extract biological knowledge in the hope of producing future publications in part. These ‘processed’ datasets are preferred, but not always required, by journals or funding agencies to be deposited in public repositories and, therefore, the fate of these datasets, including genetic maps, quantitative trait loci (QTLs) and genome-wide association study (GWAS), usually depends on the willingness of the researchers to burden themselves with formatting the data and sharing it with the larger body of researchers.
Data availability and accessibility issues are not confined to ‘Big Data’. Small datasets that are meticulously obtained in research labs, in part by taking measurements one sample at a time, are valuable, but their accessibility may be limited. Most of these datasets find their way into Supplementary Materials of individual journal articles in non-standardized formats and computationally-hard-to-process file types such as Microsoft Excel, or, worse, they stay in researchers’ individual computers or data drives, until they become obsolete, are forgotten or are simply thrown away. How would other researchers access these inaccessible datasets to harness them to further their own research for the benefit of the public, and, in the case of plants and animals, agriculture? The answer in part lies with community-centered databases and their curators, usually with PhD-level biological training, who gather, arrange, format and collate them after datasets are published, and computational personnel with domain expertise who create web-based interfaces and tools and manage publicly available sites on secured servers over networks.
In the biological data ecosystem, clade-oriented and model organism databases exist alongside large public repositories. In the plant systems, some well-known databases are The Arabidopsis Information Resource/Phoenix Bioinformatics (3) (for Arabidopsis), MaizeGDB (4) (maize), Planteome (5), Gramene (6) (multiple species), Soybase (7) and Legume Information System (8) (legumes). The funding sources for these repositories vary greatly. Similar to other countries, some databases in the USA are soft-funded with federal grants (usually by National Science Foundation or Department of Energy for plants, by National Institutes of Health for species that are more relevant for human health), and some are hard-funded by US congressional funds that provide long-term funding sustainability and long-term data safekeeping.
In this ecosystem, GrainGenes (9) (https://wheat.pw.usda.gov; Figure 1) has been hard-funded by the US Congress for over 25 years, since 1992. Its community-centric mission is serving global small grain communities by (i) acting as a centralized repository for peer-reviewed genetic, genomic, metabolic, phenotypic, transcriptomic, proteomic and trait-related data resources for genetic improvement of plants, (ii) performing community and outreach efforts through disseminating conference announcements, open positions for technicians and researchers and available assistantships for students and (iii) managing the technical infrastructure for select online resources (such as the Oat Newsletter—https://oatnews.org). GrainGenes provides stewardship for digital resources so that plant and especially small grains research can be facilitated and supported.
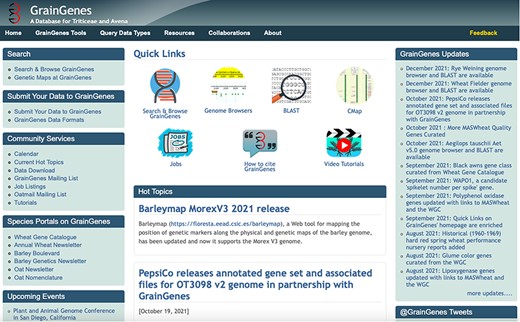
The GrainGenes’ homepage (https://wheat.pw.usda.gov) shows a wide range of services and jump points available through an intuitive, graphic interface. The top menu buttons open up new links.
GrainGenes serves a broad range of data. Historically, and still, the repository is one of the largest centralized sites in the world for small grains genetic and genomic data and encompasses data types such as genetic markers, alleles, traits, QTLs, genetic maps and, more recently, genomic sequences and variations, structural and functional annotations, genome assemblies and pangenomes. These datasets, especially the genetic sets, have been manually curated by biologist staff members [for example (10)]. When curating and managing these datasets, GrainGenes follows the findable, accessible, interoperable and reusable principles (11) to make its datasets more valuable to its users, which include the larger plant and agriculture community.
These datasets are visualized at GrainGenes through a wide range of web-based visualization applications that were implemented and customized for small grains. Some of these open-source applications were developed by the GrainGenes project members and disseminated worldwide for other researchers to freely download and use for their own research. GrainGenes prioritizes tool implementation at the site not based on where a given tool was developed but based on how well it will serve the small grains community broadly. As a simple example, GrainGenes recently strengthened its existing search capability by deploying the Google site search tool that not only facilitated the search at GrainGenes but also increased the visibility, discovery and accessibility of the data at GrainGenes through the popular Google search engine. For example, try googling ‘graingenes qtl BYDV KxO-15-a’ or ‘graingenes barley yellow dwarf virus’. Even a general search of ‘graingenes gene iron’ could provide results (try these searches with and without quotes).
In this article, we present curated data resources, computational tools, tutorials, outreach and capabilities at GrainGenes for the benefit of small grains researchers and the broader plant community.
Genomic data integration and visualization
Similar to most biological databases [for example, MaizeGDB (12)], GrainGenes went through a genomic-centric transition that accelerated in the last couple of years. Part of this transition was the implementation of new genome browsers that display assemblies and annotations as tracks. Selection of the right genome browser (13) to serve the community of interest was critical. GrainGenes opted for the Generic Model Organism Database (GMOD) project tools, which are open-source, freely available and community-driven. Among these, GBrowse and JBrowse (14, 15) are the most popular tools for displaying genomic data. GrainGenes built all the new browsers with the JavaScript-based JBrowse version 1 because it is client-based (i.e. the computational burden is on the user), fast, uses newer technologies and relies on community development. GrainGenes has yet to make the switch to JBrowse version 2 in part because of a decision to continue supporting Basic Local Alignment Search Tool (BLAST) as a service from within JBrowse using the JBrowse Connect framework, which currently only works in JBrowse 1.
New browsers, new tracks
With the cost of sequencing decreasing and the capabilities of computational tools increasing, more and more species are being sequenced, and those sequences are assembled and annotated in many biological communities, including the small grains. Consequently, GrainGenes now hosts 51 genome browsers covering wheat, barley, rye and oat species (Supplementary Table S1). Since 2019, all the genome browsers at GrainGenes have been developed in collaboration with the Triticeae Toolbox (T3) (16), reflecting the complementary missions of both databases and the willingness to devote resources to best serve their user base. These browsers are created with the data outcomes of tremendous work and effort put in by consortiums such as the International Wheat Genome Sequencing Consortium (IWGSC) (17), the Barley PanGenome Project (18) and the 10+ Wheat Project (19) among others (Figure 2).

Genome Browsers page at GrainGenes. Note that the 10+ Wheat Genome Project and Barley PanGenome Project buttons open up multiple single-assembly browsers.
It is important to note that a certain level of triage is already necessary to select sequenced species to create genome browsers and provide other services. Given the ease and the low cost of sequencing, assembly and annotation pipelines, triaging at biological databases will become more important with time. Triaging at GrainGenes focuses on the needs of small grains communities and the level of quality of the work. In some cases, the choices are straightforward, e.g. ‘first high-quality assembly of species X’. In other cases, the buy-in from a community is indicative of the importance of the work, e.g. through the establishment of a Consortium. For the in-between cases, GrainGenes relies on the guidance provided by its Advisory Board, GrainGenes Liaison Committee, that consists of scientists who are well familiar with small grains research communities.
OT3098 hexaploid oat browser
One special example among the browsers is the OT3098 hexaploid oat browser, where GrainGenes collaborated with PepsiCo and other private and public institutions to make the assembly and annotation data available through GrainGenes first for both the version 1 and version 2 genome assemblies and annotations. Although generated largely by private funds, the public can reach OT3098 data free of charge through the GrainGenes Download page (https://wheat.pw.usda.gov/GG3/graingenes-data-downloads) and GrainGenes genome browsers. GrainGenes also created a BLAST service, the results of which are linked to the OT3098 hexaploid oat browsers.
Tracks
The richness of genome browser content provides users a genomic context for regions, loci or genes of interest. In the GrainGenes genome browsers, especially in more recently sequenced and assembled species, users have access to genomic sequences of pseudomolecules and structural and functional annotation of genes. Some of our genome browsers are more richly populated than the others because they usually involve large, international consortiums. One example is the wheat reference genome Chinese Spring, created by the IWGSC (17), which has functional annotation with links to Pfam (20), InterPro (21) and AmiGO (22); links to external sites such as expVIP (23) and KnetMiner (24); and several variance tracks representing the outcomes from the Wheat Target Induced Local Lesions In Genome project (25), WHEAt and barley Legacy for Breeding Improvement (26) and MNase chromatin states (27). Another example is the Morex barley reference sequence generated by the International Barley Genome Sequencing Consortium (28). The following list includes some of the tracks available on the Morex barley genome browser: Barley Infinium 9 K single nucleotide polymorphism (SNP) markers (29), Barley 50k SNP markers (30) and Hutton 50k SNP markers (30). As part of the IWGSC Chinese Spring wheat gene assembly, we have created a unique track for expression quantitative trait loci (eQTL) data (31) that has many-to-many relationships between the expression of genes and gene loci (discussed below). To be able to represent these relationships, we created links from gene information pages to other genes (Figure 3).
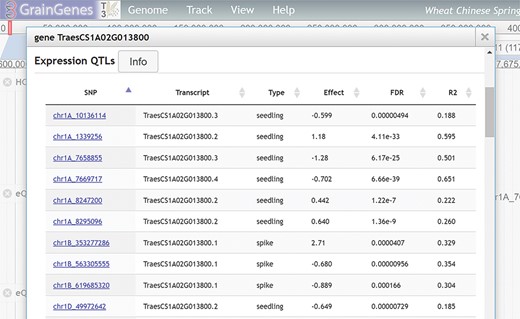
eQTL search result table in gene feature details.
G-quadruplex tracks
G-quadruplexes (G4) are formed in guanine-rich nucleic acid sequences folded into four-stranded secondary structures. G4 structures have been strongly associated with genomic and epigenetic instability (32), DNA replication (33) and gene expression (34). In Arabidopsis and rice, G4 structure folding was associated with the regulation of plant development and growth (35). Based on the biophysical studies of known G4 structures (36), canonical G4 motifs were defined as at least three consecutive guanine bases separated by flexible loop regions. In GrainGenes, G4 motif tracks are now available for wheat (IWGSC Chinese Spring RefSeq v1) (37), barley (MorexV2 and MorexV3) (38), hexaploid oat (PepsiCo OT3098 v2) and rye (Lo7 v1) (39).
Dataset project management
Browser dataset projects are managed through GitHub (https://github.com/graingenes) in private repositories, providing issue tracking and modification histories for the datasets. The repositories are private due to the repositories containing some system sensitive information. Each repository contains scripts for acquiring data, building datasets, building BLAST databases as well as JBrowse instances and genome browser configuration metadata. These files include scripts to (1) download raw data from their respective source locations (2), process and refine track data from FASTA, GFF3, VCF, BED files, etc. (3), build track metadata and configurations, build search indexes, configuration link-outs to associated external databases, banner and image graphics as such (4), process and build BLAST nucleotide and protein databases and (5) insert such configurations and process track data into our well-defined discoverable locations.
The actual raw and processed data are stored on our build/staging server, graingenes.org, not in the repositories. The raw and processed data are essentially organized on our servers in directories respective to their given repository names combined with repository scripts. We are continuously transferring and evolving new and existing scripts on our site under the GitHub project management.
As any problems, bugs, change requests and new track requests arise, they are entered as GitHub issues in their respective GitHub projects. As issues are addressed, resulting changes in scripts and files are committed and issues are closed. By utilizing this process, we keep track of how datasets were processed and what tools were used and therefore maintain a historical context.
Upon deployment, the processed data and configuration metadata are copied to our live server, wheat.pw.usda.gov, also, respectively, in their repo-named directories. Recently, we have started to use Docker (https://www.docker.com) command line and prebuilt dockerized bioinformatics tools to gain system independence and alleviate the issue of use of multi-versioned bioinformatics tools. Such tools include Sam Tools, Genome Tools, VCF tools, FASTX and BLAST from such Docker container collections as biocontainers, bschiffthaler, clinicalgenomics and cjh4zavolab. The tools are incorporated on an as-needed basis.
Genome browser framework
The genome browser framework provides a consistent look and feel for the various genome assemblies. This includes a standardized, collapsible, informational banner for displaying details about a dataset. Supplementary Table S1 shows a list of each JBrowse dataset. A dropdown genome menu within JBrowse provides access to all GrainGenes genome browsers and the framework also drives the content of the Drupal Genome Browsers page (Figure 2). The backgrounds used in the informational banners are also applied to the buttons in the Drupal Genome Browser page for cross-over consistency.
This framework also provides collapsible sub-groups for multi-genome collections, such as the Pan-barley and Wheat 10+ genomes. This serves to preserve on-screen real estate for our growing datasets while maintaining navigational consistency.
A password security system was created for browser datasets, allowing for limited access temporarily to datasets and views before the official release. Researchers are free to share their passwords with their collaborators and even with the reviewers of their manuscripts. The password protection functionality is only offered temporarily to data generators with the intent that the content, views and functionalities have been correctly built before their manuscript is published. Once a manuscript is published, GrainGenes expects the associated datasets to be shared publicly and freely.
Improved browser Linkout framework
For cross-linking with external and internal databases, we have improved the code in our datasets to link out to GrainGenes resource pages and various external databases, such as T3 (16), Pfam (20), AmiGO (22), expVIP (23), KnetMiner (24), PhyloGenes (40) and Ensembl (41). The new code is more extensible and we are moving to expand adoption throughout existing legacy datasets.
eQTL framework—special IWGSC tracks
The eQTL framework leverages GrainGenes Application Programming Interface (GGAPI) (described below) and provides a cross-reference between High Confidence v1.1 matches for Seedling and Spike eQTL tracks in wheat. A MongoDB database was created for eQTL SNP data, accessed through a RESTful interface. JBrowse plugin code results produce tables of within-feature details of the eQTLs collection of tracks, which are sortable by column. Roll-over summaries are also available on eQTL track features (Figure 3).
Pangenomes
Separate genome browsers were created for each of the genomes that were released through the 10+ Wheat and Barley PanGenome projects. For the 10+ Wheat project, only those that have full pseudomolecules were selected (10 browsers; Supplementary Table S1).
BLAST
We replaced the deprecated The National Center for Biotechnology Information (NCBI) wwwblast with the more advanced and customized Sequence Server (http://sequenceserver.com) (42), which takes advantage of the latest NCBI BLAST version and also provides new visualization of results. We designed our BLAST (43) page in such a way that BLAST results can link directly to our JBrowse datasets, where available. GrainGenes introduced a new BLAST service for our wheat, barley, oat and rye collections at https://wheat.pw.usda.gov/blast/ (see Figure 4). The new BLAST service harnesses the latest NCBI BLAST+ 2.10.0 with all our databases provided in the new version 5 database format, and processing is load-balanced by multi-threading. The new interface provides a drag-and-drop interface, a feature of multiple database selections with multiple query sequence support for multiple species. The BLAST result page shows the results of BLAST queries, identifying hit distribution and various hit details. If a dataset exists in our genome browser collection, a link will be provided to display the hit results in our JBrowse instance.
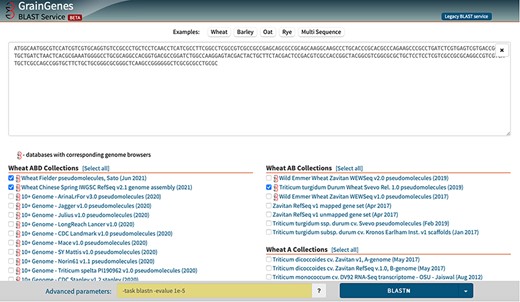
The BLAST page allows users to enter a DNA sequence and select from our database collection.
We have a collection of 120 BLAST databases, with 51 JBrowse-linked databases (where hit results have links back into our JBrowse instances). See Supplementary Table S1 for a complete list of BLAST databases.
BLAST security framework
Occasionally, we have had to secure a particular BLAST database when in stages of pre-release. A security framework was built for Sequence Server so that a database can be password protected, where the database entry is listed but is not accessible without a password.
Other computational tools
Two applications that were previously on the GrainGenes infrastructure are now accessible from the GrainGenes homepage through the Tools menu. These applications are RJPrimers (44) and BatchPrimer3 (45), which are used for transposable element junction-based PCR and other primer design strategies. Although the assemblies underlying these applications rely on the rice genome and genomic sequences of Aegilops tauschii from 2009, we were alerted to the fact that some small grains researchers still find these applications useful in their research. Hence, we created links to these applications from the GrainGenes homepage.
Improved search capabilities
GrainGenes Application Programming Interface
GGAPI, the new MongoDB-based genome browser search engine, has been implemented for genome browser feature searches and is intended to provide a more robust general search function across GrainGenes report pages and GrainGenes browsers. For the browser search function, it provides a significantly smaller footprint than the legacy browser search and has a much faster indexing capability. It also captures a richer set of search terms in descriptions, accessions, GO terms and arbitrary column-9 GFF3 attributes.
GGAPI is a RESTful service that integrates with JBrowse, while also providing a mechanism to enable other applications to use the service to find features linked to a GrainGenes Genome Browser. Currently, newer genome datasets have been implemented with the new search engine, including 20 Barley PanGenomes, Rye-lo7 v3, Morex v2 and v3 and PepsiCo QT3098 v2, with more datasets adopting it moving forward.
GGAPI currently consists of four components:
ggapi-jb: The role of this component API is to serve feature search results in a package format specified in the JBrowse REST Names API. The search results are provided in JSON format indicating the location of the query feature(s), which then informs JBrowse to navigate to a desired track and location. The service, thus, replaces JBrowse’s Names indexing feature and provides search results from our Mongo database. In preparation of each new JBrowse instance for a new grain species or cultivar, we use a tool in the module to harvest keys from the dataset into the Mongo database. The keys may be feature names, ids and any attribute.
ggapi-eQTL: This is a specialized component and was described in the ‘eQTL Framework’ section.
ggapi-probes: This API component serves to identify probes and loci that exist in GrainGenes’ MySQL database. This is generally used by our JBrowse instances, in Feature Details display, to identify whether a feature in JBrowse dataset has a report page that can be linked. Otherwise, a link is not created.
ggapi-proxy: This component is the head or front-end of GGAPI, serving as a proxy to the three other API components. It provides extensibility in that a component can be dynamically loaded or unloaded without affecting other components, providing extensibility and isolation. This enables sections of the API to be in development while maintaining the stability of other sections of the API, whereas, from the presentation perspective, they are extensions of the same API.
Google search was added to search GrainGenes pages
Along with GrainGenes Class search and browsers, our users can now search the whole website with Google at https://wheat.pw.usda.gov/cgi-bin/GG3/browse.cgi.
WheatIS search
We have added a capability to search WheatIS directly from the GrainGenes Search and Browse page at https://wheat.pw.usda.gov/cgi-bin/GG3/browse.cgi. After entering keywords, users are then directed to the WheatIS (46) results page at https://urgi.versailles.inrae.fr/wheatis/search.
Curated data content
Curators at GrainGenes are experts in plant molecular biology and genetics and are dedicated to providing accurate and informative content. To that end, curators rely on peer-reviewed publications, genetics newsletters and catalogues, and direct contributions from colleagues to populate the database. Within the GrainGenes database, the most valuable resources are mapped loci, genes and QTL that can be viewed and expanded in CMap (47), the comparative mapping tool [another GMOD (http://gmod.org) resource]. QTL maps that are decades old can now be enriched with dense consensus maps, assisting researchers to identify genes responsible for traits of interest.
QTL mapping is generally the first step to identify breeding targets and GrainGenes currently has 203 QTL maps in 40 mapdata sets. As of October 2021, there are 6621 mapped QTL records for 253 traits. These are summarized by general category, species and specific traits in Supplementary Table S2.
Topics below highlight recent curation efforts at GrainGenes:
MASWheat
As part of a mandate to link all wheat genes to the Catalogue of Gene Symbols for Wheat (https://wheat.pw.usda.gov/GG3/wgc) and (when available) protocols at the Marker-Assisted Selection in Wheat (MASWheat) project (https://maswheat.ucdavis.edu/), gene classes were selected by the curation team and all existing data were reviewed and updated with current references and links to external projects. New gene and allele records were also created and, when complete, the work was announced on the GrainGenes Updates section of the homepage.
Stripe rust curation
Wheat rusts are pathogen-caused diseases with high economic cost. Most prevalent among them are leaf, stem and stripe rust diseases. A major curation effort to bring all stripe rust genetic content in wheat is summarized at https://wheat.pw.usda.gov/GG3/content/october-2020-stripe-rust-update-graingenes.
Consensus GWAS map for stripe rust resistance
GWAS results for stripe rust resistance published since 2015 from five studies on diverse wheat collections were placed on the integrated map from Maccaferri et al. (48). These are now available on the mapdata set Wheat, Yr Update, 2021. This map set uses the Maccaferri 2015 integrated base maps, but with the entire set of QTL reported on Supplementary Table S2 for the numbered or provisionally named Yr genes. Many of the QTL were reported as simple loci with the QTL start position in ‘Wheat, Yr genes and QTL’. Markers, mapped at more than one locus, were edited to include the chromosome extension. Map units for the 2021 base maps are centiMorgans. The positions in ‘Wheat, Yr genes and QTL’ are relative to the chromosome and reported as per cent. Both positions are reported by Maccaferri et al. (48). See also: ‘Wheat, Yr genes and QTL’ for the original curation with 169 QTLs: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata&name=&id=337.
Locus/probe pages for genome assemblies
GrainGenes database records were created for five assemblies. Records in GrainGenes contain links to the locus positions on the JBrowse genome browser as well as links to external databases [Pfam (20), AmiGO (22)] that are included in the functional annotation of the gene. Likewise, gene records on the browsers contain links to GrainGenes probe records. Assemblies with curated GrainGenes database probe records are Barley, IBSC Morex v1, 2017 (49), Barley, Morex v2 Tritex, 2019 (28), IBSC Morex v3 (50), Oat, Avena atlantica and Avena eriantha assemblies (51) and Wheat IWGSC Chinese Spring RefSeq v1.0 (17).
Axiom maps
Six map sets were from Allen et al. (52). All data are linked to the reference report PBJ-15-390. These maps, originally available at CerealsDB (https://www.cerealsdb.uk.net/cerealgenomics/CerealsDB/), can now be viewed in the comparative map viewer CMap.
KASP markers for yield QTL on GrainGenes
Data including 15 yield-related QTLs, four maps, 26 KASP probes with primer information and germplasm were added to GrainGenes for Yang et al. (35). QTL mapping for grain yield-related traits in bread wheat was performed via SNP-based selective genotyping. All data are available via the mapdata page: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata;name=Wheat-2019-KASP_YldQTL.
Oat genetic and physical maps
With collaborating partners at Agriculture and Agri-Food Canada (AAFC), a major effort to curate all important genetic maps for Avena spp. resulted in 117 new map sets containing 762 maps, 21 376 markers and 785 new QTLs being added since 2018. The full list of maps for diploid and hexaploid oat can be found via the ‘Search: Genetic Maps at GrainGenes’ link on the homepage or at https://wheat.pw.usda.gov/GG3/node/876#oats6x. In addition, the curation team added or enhanced ∼300 oat germplasm records that link to T3 (https://triticeaetoolbox.org) and GRIN (https://www.ars-grin.gov) records. From these links, users can go to the T3 website and use a pedigree viewing tool for germplasm records.
Notable new map sets are discussed below:
Oat Dal x Exeter fatty acid QTL maps
Fifty QTLs for fatty acid content and agronomic traits were mapped with diversity arrays technology (DArT) on a Dal x Exeter Avena sativa population by (53).
See Oat-2012-Dal_x_Exeter mapping data for links to the maps and QTL: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata;name=Oat-2012-Dal_x_Exeter;show=locus.
Oat crown rust and powdery mildew GWAS
Nine QTLs from (54) were mapped to DArT and simple-sequence repeat markers in a GWAS analysis of 177 Spanish oat cultivars and landraces. These include five for adult resistance to crown rust, three for adult resistance to powdery mildew and one for seedling powdery mildew resistance. See GrainGenes mapdata record Oat-2015-Spanish_Pc_Pm for links to qtl and single marker/qtl maps that are available for comparison with the CMap tools: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata;name=Oat-2015-Spanish_Pc_Pm;id=480.
Oat NSGC collection GWAS maps
GWAS on 759 cultivars and landraces from the USDA National Small Grains Collection (NSGC) for Avena by (55) mapped 18 QTLs for agronomic traits and disease resistance. See Oat-2016-NSGC mapping data for links to the maps and QTL: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata;name=Oat-2016-NSGC.
Oat Pc53 maps
Pc53 for resistance to Puccinia coronata (crown rust) was mapped in two oat populations by Admassu-Yimer et al. (56). See Oat-2018-Pc53 mapping data for links to the maps: https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=mapdata;name=Oat-2018-Pc53.
Curation of the WGC
The Catalogue of Gene Symbols for Wheat, also known as the WGC, is the product of more than 50 years of curation of wheat genetic information by a group of expert wheat researchers, led by Robert A. McIntosh (https://wheat.pw.usda.gov/GG3/WGC).
The WGC is organized based on the following categories: Morphological and Physiological Traits, Proteins and Pathogenic Disease/Pest Reactions and contains information about wheat genes and gene classes, gene nomenclature, loci, alleles, QTLs, mapping and germplasm information and laboratory designations for markers, along with the associated references. The goal of the WGC is to provide helpful information about wheat genetics to a wide range of users, from researchers at the lab bench to farmers in the field.
Full editions of the WGC are compiled periodically (the last full version published in 2013), with yearly supplements. KOMUGI, the Wheat Genetics Resources Database of Japan (https://shigen.nig.ac.jp/wheat/komugi/), currently hosts an electronic version of the Catalogue and supplements up through 2017 (https://shigen.nig.ac.jp/wheat/komugi/genes/symbolClassList.jsp). GrainGenes has a dedicated page for the WGC at https://wheat.pw.usda.gov/GG3/WGC with links to the WGC documents from 1999 to 2020. In addition, the GrainGenes database contains reference records for each of the WGC editions and recent supplements (https://wheat.pw.usda.gov/cgi-bin/GG3/report.cgi?class=journal;name=Catalogue%20of%20Gene%20Symbols%20for%20Wheat;id=281).
Starting in August 2019, GrainGenes curators began curating the data in the WGC into the interactive MySQL database at GrainGenes. This work included updating existing information at GrainGenes and adding new gene classes, genes, loci, maps, references and germplasm records along with links to the KOMUGI database for gene class, gene and allele records. In addition, new information from recently published peer-reviewed publications is included. The curation team at GrainGenes submits a report of the curation work to the WGC committee on a quarterly basis to report any discrepancies observed in the information and also any new information added. Updates for this ongoing curation effort are available at https://wheat.pw.usda.gov/GG3/node/824.
A summary table of WGC curation can be found in Supplementary Table S3.
Contribution to Wheat Information System
Since 2017, GrainGenes has collaborated with the WheatIS (46) (wheatis.org) and the personnel at Unité de Recherche Génomique Info in France. Operating under the Wheat Initiative, WheatIS is a platform that provides a single hub of access through a common API to the wheat data that are distributed among the small grains databases worldwide. A shortcut to all GrainGenes data at WheatIS can be found at https://urgi.versailles.inra.fr/wheatis/#result/term=graingenes. Through its local node, GrainGenes indexed:
Germplasm. 16 106 germplasm records including lines from the Global Tetraploid Wheat Collection, and all other diploid, tetraploid and hexaploid accessions in GrainGenes.
QTLs. 3925 QTLs, of which 3408 are new, and the previous 548 have enhanced descriptions.
Genetic Maps. 147 genetic maps, of which 56 are new.
Physical Maps. 12 physical maps, of which two are new.
WGC. As a service to the small grains community, 3119 genes from the WGC point to specific gene pages at the KOMUGI database in Japan.
Nursery reports
Uniform regional nursery data
The following reports were uploaded to GrainGenes and can be found at https://wheat.pw.usda.gov/GG3/germplasm:
2019 Uniform Regional Scab Nursery for Spring Wheat Parents.
2020 Uniform Regional Hard Red Spring Wheat Nursery reports.
2020 Uniform Regional Scab Nursery for Spring Wheat Parents.
Mississippi valley barley nursery reports
We have added several Mississippi Valley Barley Nursery Reports covering the years between 1999 and 2014 for agronomic traits and malting quality. These reports can be reached on our Germplasm page following this link: https://wheat.pw.usda.gov/GG3/germplasm#barley.
Service to the small grains community
GrainGenes is not only a centralized repository for small grains data but also a digital platform for other repositories and community newsletters:
Annual Wheat Newsletter. GrainGenes hosts the Annual Wheat Newsletter issues published since the 37th issue in 1991 (https://wheat.pw.usda.gov/ggpages/awn/). Wheat Annual Newsletter Volume 67 (2021) was recently made available.
Barley Genetics Newsletter. GrainGenes has hosted the Barley Genetics Newsletter issues since the first issue in 1971 (https://wheat.pw.usda.gov/ggpages/bgn/). The most recent Barley Genetics Newsletters, v48 (2018) and v49 (2019–2020), created by Phil Bregitzer and Udda Lundqvist, are now available at GrainGenes.
Oat Newsletter. We host a site for the Oat Newsletter that has been published since 1950. The Newsletter was converted into a website where it not only hosts research reports and old issues but also blog entries by oat researchers (https://oatnews.org).
USDA-ARS Small Grains Genotyping Labs. This is the website describing the four ARS genotyping labs in the USA. They use the site for general information, links and contact information (https://wheat.pw.usda.gov/GenotypingLabs/).
Grains email list. The grains mailing list consists of 1057 members working on wheat, barley, oat and related species. It has operated since 1992. Messages are curated by GrainGenes personnel.
OatMail email list. OatMail is a new email list that consists of 90 members working on oat. Messages to the OatMail list are curated by Charlene Wight and GrainGenes personnel. OatMail is jointly administered with the Oat Newsletter and AAFC Canada to facilitate communication between members of the oat research community.
Outreach and training
Since GrainGenes’ mission is to serve small grains researchers, interacting with them through scientific conferences to learn their priorities and concerns and keep up with the ever-changing research landscape is a priority. Consequently, GrainGenes personnel attend many conferences in person (although due to the coronavirus disease 2019 pandemic, there has been a hiatus) to give talks on GrainGenes. In addition, GrainGenes personnel give guest lectures at workshops, as well as in undergraduate and graduate classes. We have presented at the University of California, Davis, the University of California, Berkeley, and Montana State University. To reach a geographically broader audience, GrainGenes personnel also create training videos and upload them to the ‘GrainGenes Official’ channel on YouTube. Since 2019, the following four tutorials were created and made available on YouTube as well as at GrainGenes (https://wheat.pw.usda.gov/GG3/tutorials):
‘Navigating between GrainGenes Database Records and Genome Browsers’.
‘Saving Information from Genome Browsers in GrainGenes’.
‘Using CMap in GrainGenes to Improve Marker Density around a Gene of Interest’.
‘How to submit data to GrainGenes’.
Collaborations
GrainGenes is actively involved in both the Steering Committee and Working Groups of the AgBioData Consortium (57) (https://www.agbiodata.org) that was formed by agricultural databases to develop solutions to common issues for biological repositories such as developing data/metadata standards, gene naming nomenclatures and data sharing practices. Another collaboration to which GrainGenes is actively contributing is the WheatIS (46), operating under the International Wheat Initiative (wheatis.org). GrainGenes also works with Ag Data Commons (https://data.nal.usda.gov), which is under the National Agricultural Library of the US Department of Agriculture, to house, organize and make data accessible to the public.
Conclusion
GrainGenes is the flagship repository of the US Department of Agriculture for genetics and genomics data for small grains. Although it is primarily funded by hard funds apportioned by the US Congress, its mission is to serve the global small grains research communities for the improvement of agriculture, crop development and contribution to food production.
GrainGenes houses small grains data for Triticeae and Avena species, such as wheat, barley, rye and oat. It has a wide range of data types, including genetic (genetic markers, maps and QTLs), genomic (assemblies, functional and structural annotations and genomic elements) and ontology datasets. Community outreach is part of GrainGenes’ mission, so users also have access to tutorials, job boards, meeting announcements and information about community initiatives.
In the future, we expect not only more assemblies and annotations for more small grains species, but also pangenomic and phenotypic, metabolic pathway, protein–protein network and, with the recent watershed publication of DeepMind AlphaFold (58), protein structural data. The access to standardized data and the ability to search, query and extract data/metadata information will be an ongoing challenge, along with the bigger challenge of reaching information across separate databases. Initiatives such as AgBioData and WheatIS are steps in the right direction to find solutions to problems common among biological databases and apply those solutions for the benefit of a global user base.
In this article, we presented an update of the genomic and genetic data resources, computational tools, improvements to infrastructure and web interface, and outreach efforts at GrainGenes that small grains researchers and the larger plant community can access and use for crop improvement to respond to the food needs of the rising population worldwide within the context of the environmental uncertainties associated with climate change.
Supplementary data
Supplementary data are available at Database Online.
Acknowledgements
GrainGenes is supported by the United States Department of Agriculture—Agricultural Research Service (USDA-ARS) under the CRIS project 2030-21000-024-00D. Mention of trade names or commercial products is solely for the purpose of providing specific information and does not imply recommendation or endorsement by the USDA. USDA is an equal opportunity provider and employer. GrainGenes benefits significantly from the oversight provided by the members of the GrainGenes Liaison Committee: Mark Sorrells (Chair), Jorge Dubcovsky, Catherine Howarth, Kevin Smith and Roger Wise. The opinions in this study are those of the authors and do not necessarily represent the opinions or policies of PepsiCo, Inc. All URLs were accessed in November 2021.
Funding
United States Department of Agriculture—Agricultural Research Service (2030-21000-024-00D).
Conflict of interest
None declared.

{kind=link}
{kind=link}
{kind=link}
{kind=link}