





Abstract
The BioRED track at BioCreative VIII calls for a community effort to identify, semantically categorize, and highlight the novelty factor of the relationships between biomedical entities in unstructured text. Relation extraction is crucial for many biomedical natural language processing (NLP) applications, from drug discovery to custom medical solutions. The BioRED track simulates a real-world application of biomedical relationship extraction, and as such, considers multiple biomedical entity types, normalized to their specific corresponding database identifiers, as well as defines relationships between them in the documents. The challenge consisted of two subtasks: (i) in Subtask 1, participants were given the article text and human expert annotated entities, and were asked to extract the relation pairs, identify their semantic type and the novelty factor, and (ii) in Subtask 2, participants were given only the article text, and were asked to build an end-to-end system that could identify and categorize the relationships and their novelty. We received a total of 94 submissions from 14 teams worldwide. The highest F-score performances achieved for the Subtask 1 were: 77.17% for relation pair identification, 58.95% for relation type identification, 59.22% for novelty identification, and 44.55% when evaluating all of the above aspects of the comprehensive relation extraction. The highest F-score performances achieved for the Subtask 2 were: 55.84% for relation pair, 43.03% for relation type, 42.74% for novelty, and 32.75% for comprehensive relation extraction. The entire BioRED track dataset and other challenge materials are available at https://ftp.ncbi.nlm.nih.gov/pub/lu/BC8-BioRED-track/ and https://codalab.lisn.upsaclay.fr/competitions/13377 and https://codalab.lisn.upsaclay.fr/competitions/13378.
Database URL: https://ftp.ncbi.nlm.nih.gov/pub/lu/BC8-BioRED-track/https://codalab.lisn.upsaclay.fr/competitions/13377https://codalab.lisn.upsaclay.fr/competitions/13378
Introduction
Biomedical relation extraction plays a pivotal role in discerning and categorizing relationships between biomedical concepts from textual data. This task stands central to biomedical natural language processing (NLP) [1], fostering advancements in areas like drug discovery [2] and personalized medicine [3].
BioCreative challenges have embraced the relation extraction tasks since BioCreative II in 2007, as shown in Fig. 1. The BioCreative II PPI task [4] focused on the automated extraction of protein–protein interaction information from biomedical literature. The BioCreative II.5 IPT task [5] explored the integration of user interaction with automated systems for improved information extraction. Moving forward, the BioCreative IV CTD and BioCreative V CDR tasks [6] delved into identifying chemical-induced-disease relationships. The BioCreative VI PM task [7], centered on precision medicine, aimed to extract protein–protein interaction information affected from the presence or absence of a mutation from biomedical texts. And finally, in 2021, the BioCreative VII DrugProt task [8] addressed drug–protein interactions in the context of drug discovery.
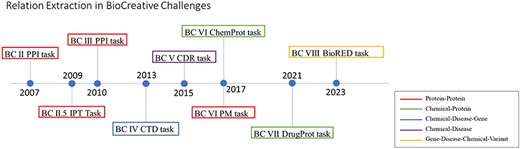
A timeline of BioCreative challenges and the relation extraction community tasks.
However, prior BioCreative challenges and other publicly available benchmark datasets for relation extraction typically focus on single-type relations, usually within the confines of a single sentence or short context. The recently published BioRED dataset [9] encompassed a broader coverage than the previous corpora, in that it captured multiple entity types (like gene/protein, disease, and chemical) and document-level relation pairs amongst the entities (such as, gene–disease and chemical–chemical). Furthermore, beyond relation pair extraction, BioRED also included annotations for novel findings, distinguishing relations that constitute the main contributions of an article from pre-existing knowledge.
It is notable that automated methods to recognize relationships in biomedical publications have a long history. While previous community challenges [4, 6–8, 10–12] focused on identifying relationships of a single entity pair, biomedical text is typically rich in entities of multiple categories, such as genes/proteins, diseases/phenotypes, chemicals/drugs, etc, and relationships encountered in any given document generally occur between different entity types. While previous studies focused on relationships between entities mentioned in the same sentence [13], often document understanding involves recognition of relationships that span the whole document and perusal of the whole document provides valuable additional detail. While many previous studies did not require entity normalization [14–16], real-world applications necessitate that entities are linked to specific knowledge base records, and finally, biocuration efforts [17], and other knowledge discovery studies [18, 19] often distinguish between novel findings and background information.
The BioRED track at BioCreative VIII challenge consists of two distinct subtasks:
Subtask 1: the participants are asked to build automatic tools that can read a document (journal title and abstract) with preannotated entities, and identify the pairs of entities in a relationship, the semantic type of the relationship, and its novelty factor;
Subtask 2: the participants are asked to build an end-to-end system where they were only provided with the raw text of the document, and they are required to detect the asserted relationships, their semantic relation type, and the novelty factor.
Since the original 600 articles in BioRED were publicly released, during this track, we expanded the BioRED dataset to 1000 PubMed articles, by using the complete previous BioRED as training data, while providing an additional 400 articles published between September 2022 and March 2023 as a testing dataset.
Material and methods
We announced the BioCreative VIII BioRED challenge in Spring 2023. The training BioRED corpus was made available as the training dataset in March 2023. A webinar was held in June 2023 to introduce the motivation of the challenge and associated data to the interested teams. The testing dataset, which complements the previously annotated 600 articles of the BioRED corpus, was manually annotated in April–August 2023. All materials provided to the participants, including a recording of the webinar, are publicly available at https://ftp.ncbi.nlm.nih.gov/pub/lu/BC8-BioRED-track/.
The BioRED-BC8 dataset
The BioRED-BC8 dataset articles span a variety of journals, are rich in the coverage of biomedical entities, and span a wide range of biomedical-related topics to be representative of biomedical literature publications that contain relationships between biomedical entities. We describe the BioRED-BC8 dataset in detail in the work by Islamaj (2023) [20], but here we give a brief overview.
The original BioRED dataset is provided as the training dataset. To help the challenge participants, we set up two leaderboards [21, 22] for system development at the CodaLab site, where the dataset is separated into training (500 articles) and validation (100 articles) datasets. Because the BioRED dataset is publicly available, we masked the article identifiers for all the articles, and the validation set articles were hidden amongst a set of 1000 PubMed articles. The evaluation script was carefully tuned to only assess the validation set articles when computing the statistics to rank the teams. The challenge data were provided in three formats: PubTator [23], BioC-XML, and BioC-JSON [24], and participant teams could use any of them.
The test dataset articles were specifically selected to meet three criteria. (i) Open access compliance: the articles were selected to ensure there are no restrictions on sharing and distribution. (ii) Optimized for method development: the selected articles are enriched with bioentities and their relations, providing an ideal dataset for developing and refining text mining algorithms. (iii) Real-world applicability: the focus on recently published articles ensures the dataset is suitable for testing real-world tasks, reflecting current trends and challenges in biomedical research.
For the BioRED track evaluation, we selected PubMed documents published in the recent 6 months before the challenge. We anticipated that these abstracts would reflect current trends in biomedical research. We collaborated with eight NLM biocurators (with 20 years biomedical indexing as their profession on average) to manually annotate 400 abstracts with biomedical entities linked to their corresponding database identifiers (gene/proteins normalized to NCBI GENE [25], diseases normalized to MeSH [26], chemicals to MeSH, genomic variations to dbSNP [27], species to NCBI Taxonomy [28], and cell lines to Cellosaurus [29]) and all binary relationships between them, as specified in the BioRED annotation guidelines. Because all relationships are defined at the document level, the two entities in a relationship are identified with the corresponding database identifiers, as opposed to the text mentions. All articles were doubly annotated, and the corpus annotation was conducted in two phases: Phase 1: the annotation of all biomedical entities (text span and database identifiers) in a three-round annotation process, and then, after all articles were reshuffled and redistributed to pairs of biocurators; Phase 2: the annotation of biomedical relationships (semantic type and novelty factor) in a three-round annotations process. In Table 1, we show the data statistics of the BioRED track train and test dataset.
Data statistics for the BioRED track train and testing dataset. For each element, we list total and unique numbers
| Annotations | BioRED train | BioRED test |
|---|---|---|
| Documents | 600 | 400 |
| Entities | 20 419 (3869) | 15 400 (3597) |
| Gene | 6697 (1643) | 5728 (1278) |
| Disease | 5545 (778) | 3641 (644) |
| Chemical | 4429 (651) | 2592 (618) |
| Variant | 1381 (678) | 1774 (974) |
| Species | 2192 (47) | 1525 (33) |
| Cell line | 175 (72) | 140 (50) |
| Relation Pairs | 6502 | 6034 |
| Disease–Gene | 1633 | 1610 |
| Chemical–Gene | 923 | 1121 |
| Disease–Variant | 893 | 975 |
| Gene–Gene | 1227 | 936 |
| Chemical–Disease | 1237 | 779 |
| Chemical–Chemical | 488 | 412 |
| Chemical–Variant | 76 | 199 |
| Variant–Variant | 25 | 2 |
| Pairs describing novel relationships for the context as opposed to background knowledge | 4532 | 3683 |
To ensure test data integrity, we compiled a large dataset of 10 000 documents, and the manually annotated 400 documents were concealed within this large set. Only that 400 articles were used to compute the evaluation metrics.
Benchmarking systems
In our previous work [30], we described an improved relationship extraction tool called RioREx, which was based on a BERT model with data adjustment rules. BioREx proposes a data-centric approach that bridges annotation discrepancies between data sources and amalgamates them to construct a rich dataset of adequate size. Despite the diversity in annotation scope and guidelines, BioREx systematically consolidates disparate annotations into one largescale dataset.
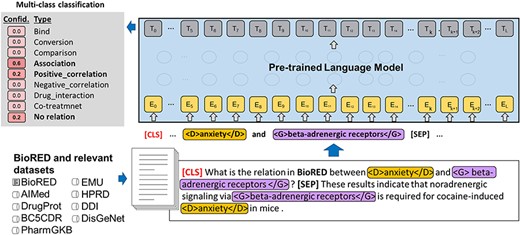
Intrigued with the prospect of testing these previous models on a real-world dataset, we evaluated both systems on the BioRED-BC8 test dataset. In addition, with the rise of large language model (LLM) systems [31], we also tested the Generative Pre-trained Transformer (GPT) systems for biomedical relation extraction. We describe in detail these systems in the work by Lai (2023) [32] and here we give a short summary of the relation extraction formulation in the following images, and summarize their results in the results section in Tables 2 and 3.
PubMedBERT-based model: as illustrated in Fig. 2, PubMedBERT treats both subtasks as multiclass classification tasks. Given a pair of entities represented by their normalized IDs and the article text (title and abstract), PubMedBERT predicts a classification using the [CLS] tag. BioRED model, in this context, produces two outputs: the relation type label and the novelty prediction label. The difference in the application of this model for subtask 2 is that instead of the human annotations of the entity labels and their identifiers, we use the entity predictions as extracted from the PubTator APIs.
BioREx-based model: we illustrate the BioREx model in Fig. 3. BioREx is trained on nine combined datasets, and produces one classification result, that of the relation type. BioREx cannot produce multiple labels, so we are not able to address the novelty label classification problem, and therefore these results contain only the relation type classification.
GPT-based model: Fig. 4 illustrates the prompts we used for the GPT-based model. The GPT prompts involved a series of explanations to set up the Large Language Model (LLM) for relation prediction. The data to the LLM were presented one article at a time (title and abstract). The initial instructions, presented as Passage 1, listed the annotated entities in the article text, specifying their types and their corresponding normalized database identifiers. “Passage 2 (Main Article)” provided the given article. Following that, Questions 1 and 2 were designed to define the relation types and the novelty labels.

PubMedBERT model illustration of the formulation of the relation extraction task.
An illustration of relation task formulation of BioREx.
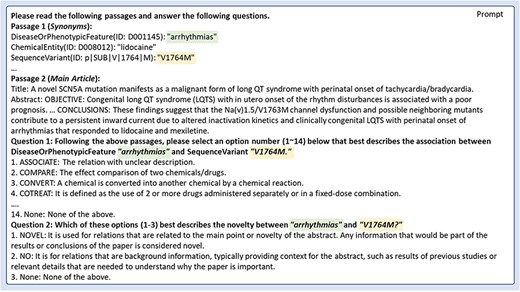
An illustration of prompt input for OpenAI GPT-3.5 and GPT-4.
Results of benchmarking systems for Subtask 1 (in %). Please note the highest F-score value (BioREX) and how it compares with the Large Language Model systems
| Subtask 1 | Entity pair | Entity pair +relation type | Entity pair +novelty | All | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | P | R | F | P | R | F | P | R | F | P | R | F |
| GPT 3.5 | 23.07 | 99.35 | 37.44 | 8.26 | 35.58 | 13.41 | 14.06 | 60.57 | 22.83 | 5.36 | 23.08 | 8.70 |
| GPT 4 | 27.57 | 96.88 | 42.93 | 13.39 | 47.05 | 20.85 | 19.52 | 68.60 | 30.40 | 9.92 | 34.85 | 15.44 |
| PubMedBERT | 72.03 | 76.71 | 74.29 | 50.34 | 53.61 | 51.93 | 54.54 | 58.08 | 56.25 | 37.71 | 40.16 | 38.90 |
| BioREx | 76.83 | 74.56 | 75.68 | 57.76 | 56.05 | 56.89 | – | – | – | – | – | – |
Results of benchmarking systems for Subtask 2 (in %). For Subtask 2, since we are not given manual annotation of entities, we used PubTator 3 to retrieve these predictions. The highest F-score is highlighted
| Subtask 2 | Entity pair | Entity pair +relation type | Entity pair +novelty | All | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | P | R | F | P | R | F | P | R | F | P | R | F |
| GPT 3.5 | 18.93 | 74.71 | 30.21 | 6.78 | 26.75 | 10.81 | 11.74 | 46.32 | 18.73 | 4.47 | 17.65 | 7.14 |
| GPT 4 | 22.56 | 73.22 | 34.49 | 11.14 | 36.16 | 17.04 | 16.15 | 52.40 | 24.69 | 8.35 | 27.10 | 12.77 |
| PubMedBERT | 55.49 | 47.98 | 51.46 | 39.67 | 34.30 | 36.79 | 41.69 | 36.05 | 38.66 | 29.76 | 25.73 | 27.60 |
| BioREx | 59.26 | 49.49 | 53.94 | 44.65 | 37.29 | 40.64 | – | – | – | – | – | – |
Evaluation measures
The evaluation metrics used to assess team predictions were micro-averaged recall, precision, and F-score (main evaluation metric). Three different result types were scored: false-negative (FN) results corresponding to incorrect negative predictions, false-positive (FP) predictions corresponding to incorrect positive predictions, and true-positive (TP) results corresponding to correct predictions. Recall R = TP/(TP + FN). Precision P = TP/(TP + FP). The F-measure F = 2· P · R/(P + R).
We measure the precision, recall, and F-scores for these settings: (i) entity pair: to evaluate the correct pairs of entities that are in a relationship, (ii) entity pair + relationship type: once the correct pairs have been identified, to evaluate the correct semantic relationship that the two entities engage in, and for novelty, (iii) entity pair + novelty: once the correct pairs have been identified to evaluate the correct pairs in a novel relationship, and (iv) all: once the correct pairs and the correct semantic relationship type have been identified to evaluate the novelty factor. For Subtask 2, all these evaluations require that the entities are correctly identified and normalized to their corresponding database identifiers.
The evaluation script was made available to all track participants, together with the data and other challenge materials via: FTP: http://ftp.ncbi.nlm.nih.gov/pub/lu/BC8-BioRED-track; CodaLab: https://codalab.lisn.upsaclay.fr/competitions/13377; and https://codalab.lisn.upsaclay.fr/competitions/13378.
Challenge participation and team descriptions
Fourteen teams worldwide submitted a total of 56 runs for Subtask 1, 19 of which were submitted after the deadline, and were considered unofficial. For Subtask 2, nine teams submitted a total of 38 runs, nine of which were considered unofficial because they were submitted after the deadline. Team participation is illustrated in Fig. 5.
Team participation for the BioRED track at BioCreative VIII.
Team 114: DETI/IEETA, University of Aveiro, Tiago Almeida and Richard A. A. Jonker
We participated in the BioRED track, Subtask 1. Our team designed a unified model [33] capable of jointly classifying relations and detecting whether this relation is novel [34]. Our architecture leverages the BioLinkBERT [35] model as a backbone to generate robust contextualized representations for each entity. Prior to feeding the input sequence to the model, we surround each entity with special tokens “[s1],[e1],[s2],[e2]” to denote the start and end of each entity. From these special tokens’ contextualized embeddings, we create a comprehensive representation by aggregating individual entity representations through a multihead attention layer. This combined representation is then inputted into two separate classifiers: one for relation classification and the other for novelty detection. Both classifiers are trained using a combined loss function. The loss for the novelty classifier is only considered when a relation exists between the two entities.
For training the relation classifier, we introduce an additional class for entities that do not have a relation between them, which we call the negative class. To maintain dataset balance, we restricted the number of negative relations to match the total number of relations in the remaining classes. However, empirical findings revealed that using twice the amount of negative classes enhanced the performance of our joint model. Negative relations were randomly sampled, and the choice of seed significantly impacted the model’s performance. Additionally, during negative sampling, we only consider pairs that could potentially be related according to the guidelines [20]. We do not perform novelty classification for classes that belong to the negative class.
To enhance overall system performance, we employed ensemble techniques to combine the outputs of our various trained models. For the ensemble, we used two majority voting systems: the first to decide if the relation exists and determine the class of the relation, and the second to vote on the novelty of the relation given the relation class. Finally, we submitted five runs to the competition, including the two best-performing models on validation data and three ensemble models. The model that performed best in the competition, achieving an F1 score of 43.50%, was our top model during validation. This model leverages BiolinkBERT-large as its backbone and incorporates negative sampling and special tokens in its training process. Our ensemble models obtained similar performances.
Team 154: LASIGE, Universidade de Lisboa, Sofia I. R. Conceição and Diana F. Sousa
Our team’s lasigeBioTM [36] submitted for both subtasks. Our primary approach focused on the relation extraction phase employing K-RET [37]. K-RET uses external domain knowledge in the form of ontologies to enhance BERT-based systems. This system allows flexible integration of the knowledge, allowing the use of diverse sources, where to apply it, and the handling of multitoken entities. Thus, K-RET can extend the sentence tree without altering the sense of each sentence. We used the pretrained allenai/scibert_scivocab_uncased SciBERT [38] model and independently fine-tuned it for the association and novelty labels.
For Subtask 1, we used K-RET with the SciBERT pretrained model together with knowledge from five different ontologies that cover the majority of the dataset entities type: gene ontology [39, 40], chemical entities of biological interest [41], human phenotype ontology [42], human disease ontology [43], and NCBITaxon ontology [44]. For Subtask 2, besides the use of the K-RET system, we employed HunFlair [45] for Named-Entity Recognition (NER) and dictionaries for Named-Entity Linking (NEL) with an edit Levenshtein distance of 2.
Our results were significantly lower than the task’s average and median performance. Our model struggled to predict low representative labels, indicating that it is heavily dependent on a large number of examples. Also, the lack of our teams’ computational resources led to slower runs, which did not give us the time to run and experiment on multiple configurations.
Team 118: National Cheng Kung University, Cong-Phuoc Phan and Jung-Hsien Chiang
Our methodology [46] comprises two primary elements: a probability model for identifier matching in NER task and the application of ensemble learning methods to BioRED [9] and BioREx [30] models. These models, trained on augmented data, are utilized for relation extraction tasks.
The probability model is constructed based on the likelihood of coexisting k identifiers. It assesses how an entity, with a specific identifier match, belongs to the article’s annotation list. For simplicity, k is statically set to 2 in this method. However, it can be adjusted to other values depending on the size and length of the data, necessitating further research. One limitation of this approach is that the paragraph must be partially annotated for the probability model to estimate whether a new entity with a matched identifier has a chance to be included in the annotation list. To address this limitation, the AINOER [47] model is exploited to generate entities and a basic transformer model that is trained on multiple datasets (OMIM, MeSH, NCBI, and dbSNP), and then is used for initial entity identifiers matching. This temporary workaround is opened for future development.
In the context of relation extraction tasks, the BioRED and BioREx models are trained on augmented data generated by ChatGPT, Claude, and BingChat. To preserve the meaning and defined entities from NER steps, each article undergoes preprocessing to align entities and ensure the augmented data contains a correct entity list. The trained models are then employed to predict relations between entity pairs and label each relation as novelty or non-novelty using two approaches. The first approach predicts novelty from detected relations, while the second predicts novelty from entity pairs and filters to retain only those pairs present in detected relations.
Team 129: Dalian University of Technology, Jiru Li and Dinghao Pan
The DUTIR-901 team [48] participated in both subtasks of the BioRED track. We built a multitask method that defines the intermediate steps of relationship extraction as various subtasks, used for joint training of the model to enhance its performance. We utilized PubMedBERT for context encoding, specifically, for each document, we inserted “[CLS]” at the beginning and “[SEP]” at the end of the text. For every entity pair within the document, we constructed a sample, regardless of whether they had a relationship. For each mention in the sample, we inserted special symbols “|$@\backslash {\rm{E}}$|” and “|${\rm{E}}/@$|” to identify the positions of mentions. During the training process, we filtered out samples that involved entity pair types for which no candidate relationships exist. We tokenized the document, and input it at the token level into the PubMedBERT model to obtain encoded representations of the text.
During training, our multitask approach included a coreference resolution step, which ascertained whether textual references corresponded to the same entity and category-based tasks such as entity pair identification, novelty identification, and relation extraction. To enhance the performance and robustness of the single model, we used an adversarial training approach after loss backpropagation. Furthermore, we employed a model ensemble approach. We trained multiple models based on the K-fold cross-validation and integrated the results of each model’s predictions using a voting method.
By jointly learning all of the above tasks, our model effectively captured the context and identified the relationships. Our approach not only improved the quality of relationship extraction but also enhanced the accuracy in classifying the novelty of entity pairs. Our method achieved an F1 score of 44.41% on Subtask 1 and 23.34% on Subtask 2. Combining the PubTator API with this multitask approach, we built a relation extraction system that did not rely on manually annotated entities.
Team 127: National Central University, Taiwan, Wilailack Meesawad and Richard Tzong-Han Tsai
We propose an ensemble learning approach [49], combining the PubTator API with multiple pretrained Bidirectional Encoder Representations from Transformers (BERT) models. Our system for Subtask 1 relies on the open-source relation extraction (RE) system following the BioRED paper [9]. A relation candidate instance consists of two biomedical entities and the context of their co-occurrence. Initiating the development of an end-to-end system (Subtask 2), we leverage the PubTator API to access pivotal biomedical concepts and entity IDs. These concepts and IDs are standardized to align with the dataset format. For dataset normalization, specific terms like “ProteinMutation,” “DNAMutation,” and “SNP” are consolidated under “SequenceVariant.” Additionally, “Chemical” is unified as “ChemicalEntity,” “Disease” as “DiseaseOrPhenotypicFeature,” “Gene” as “GeneOrGeneProduct,” and “Species” as “OrganisationTaxon.” Entity ID transformations involve removing prefixes like “MESH:” and “tmVar” and standardizing notations, such as changing “CVCL:” to “CVCL_” and “RS#:” to “RS.”
This study uses PubMedBERT [50], which is a state-of-the-art pretrained language model with specialization in the medical domain, to fine-tune a text classification model on the BioRED dataset. Utilizing pretrained models from Subtask 1, we predict on the processed output. Extensive preprocessing of sentence pairs is conducted to enhance model performance. Each instance comprises two sentences: the first (Sentence 1) is the generated prompt question or entity ID pair, while the second (Sentence 2) describes a co-occurrence context. Boundary tags are inserted to denote entities (e.g. <GeneOrGeneProduct> and </GeneOrGeneProduct>). We ensure these tags remain intact by adding them to the pretrained language model’s vocabulary. Additionally, special tokens “[CLS]” and “[SEP]” are included at the instance’s beginning and between Sentence 1 and Sentence 2, adhering to standard pretrained BERT model usage for classification tasks.
Enhancing prediction quality and reliability, we apply the Max Rule ensemble learning mechanism, aggregating confidence scores from multiple models with different preprocessing inputs. This mechanism ensures the final prediction is based on the class with the highest probability score, boosting result robustness and accuracy. Employing the relation type classifier’s predictions, we generate the submission file. Instances indicating a relationship but classified as “None” for novelty are categorized as “Novel,” denoting new findings in medical text. Our method achieves an F1 score of 43% in Subtask 1 and 23% in Subtask 2, signifying substantial progress in biomedical relation extraction.
Team 157: University of Illinois at Urbana-Champaign, IL, USA, M. Janina Sarol and Gibong Hong
We developed an end-to-end pipeline [51] that sequentially performs named entity recognition, entity linking, relation extraction, and novelty detection. Our named entity recognition system is a fine-tuned PubMedBERT [50] model that performs BIO type tagging (e.g. B-ChemicalEntity, I-CellLine). We apply additional postprocessing rules to the model predictions by merging (i) consecutive spans of entities of the same type and (ii) disease entities separated by a single whitespace character into a single entity.
The entity linking component uses PubTator Central (PTC) [52] to map gene, protein, and disease mentions, and BERN2 [53] for chemicals, cell lines, species, and variants. We utilized PTC as a lookup table; for each entity mention found by our NER model, we searched the PTC results for exact span matches. As our NER model already identifies entity mentions, we only utilized the normalization component of BERN2, passing entities found by our NER model as input.
Our relation extraction and novelty detection models are document-level adaptations of the PURE [54] model, which was originally tailored for sentence-level relation extraction. We modified the model to take information from multiple entity mentions, while prioritizing mentions that are more important for relation prediction. In addition, since the BioRED relations are nondirectional, we eliminated the distinction between subject and object for entities. Finally, we used projected gradient descent attacks [55] during training to improve the robustness of our models.
Team 142: Higher School of Economics, Russia, Airat Valiev and Elena Tutubalina
We participated in Subtask 1 and evaluated two models with general BERT [56] and PubMedBERT [50] architectures, which we call: (i) basic BERT classifier; and (ii) BioRED model [9].
The first model utilizes the simple transformers library [57]. It encodes the input text between two entities (both entities from a relation are tagged with special tokens to highlight the pair in the input text) and uses a softmax layer. The model with PubMedBERT demonstrated significant improvements over the BERT-based classifier: PubMedBERT-based model trained with 20 epochs and batch size of 8 achieved 63.6% F1 on a validation set, while the general BERT-based model trained with 15 epochs and batch size of 8 achieved 52.88% F1 on a validation set.
The BioRED model functioned the following way: the input documents are first split into multiple sentences and encoded into a hidden state vector sequence by PubMedBERT. First, it uses two tags, [SourceEntity] and [TargetEntity], to represent the source entities and target entities. Then, the tagged abstract turns to a text sequence as the input of the models. We use the [CLS]’s hidden layer and a softmax layer in the classification. This classifier with PubMedBERT checkpoint was trained on two train sets separately: (i) the BioRED train set provided by the BioCreative VIII organizers (600 abstracts), (ii) BioREx dataset [30] (more than 9000 abstracts with relation types and novelty information). This second approach showed improvement over the model trained on the BioRED corpus only: the model trained on a combined set of BioRED and the rest of the BioREx corpora with the same hyperparameters (20 epochs, batch size of 8) achieved 74% F-scores versus 67% on a test set, respectively.
Additionally, we tried ChatGPT 3.5, yet ChatGPT’s performance on a subset of the validation set was nearly two times worse than PubMedBERT.
To sum up, as our team’s competition results, we’ve made two predictions with the BioRED-train-set baseline and BioREx-train-set model, and the test results obtained were 67% F-1 and 0.74% F-1, respectively.
Team 138: Miin Wu School of Computing, National Cheng Kung University, Taiwan, Yi-Yu Hsu and Shao-Man Lee
Our method [58] utilized advanced NLP models, including PubMedBERT [50], BioBERT [59], AIONER [47], and BioSyn [60], in conjunction with Named Entity Recognition (NER) and Named Entity Normalization (NEN) techniques. This combination resulted in substantial improvements in both entity identification and normalization processes. Additionally, we incorporated GPT-4 to augment the training data and implemented a selective dual training strategy specifically focusing on chemical entities. This targeted approach not only improved efficiency but also led to enhancements in performance metrics. To address common challenges such as data offset inaccuracies and formatting inconsistencies, we employed practical solutions.
Expanding upon BioRED’s annotated data, our approach addresses biomedical relation extraction through three key stages: NER, NEN, and RE. To combat inaccurate tokenization of specialized terms like “p.G380R,” we utilized “nltk.tokenize.RegexTokenizer” with custom rules. Further, leveraging domain-specific models such as BioBERT and AIONER, which were trained on biomedical data, significantly enhanced NER performance. In NEN, we assigned unique identifiers using BioSyn’s synonym marginalization to account for synonymous terms. Our curated vocabulary played a crucial role in ensuring accurate entity identification. This combined approach establishes a robust foundation for downstream tasks by resolving tokenization and synonym-related challenges in biomedical text processing.
By harnessing GPT-4, we synthesized BioRED-like data for efficient model training. Through dialogues and specific prompts, we guided GPT-4 to generate data, ensuring accuracy in the process. Strategies like data augmentation and targeted content creation were employed to address challenges such as formatting inconsistencies and to enrich diversity. Additionally, a dual-training approach significantly improved chemical entity prediction. The integration of data synthesis with GPT-4, fine-tuned PubMedBERT, and targeted content creation resulted in an F1 score of 40% in Subtask 1, marking a significant advancement in biomedical relation extraction. This not only highlights the effectiveness of our approach but also underscores the critical role of accurate chemical entity predictions in overall model performance improvement.
Team 158: RMIT University, Australia, Mingjie Li and Karin Verspoor
In this study, we participated in the BioRED track’s Subtask 1, focusing on the evaluation of two models: one employing vanilla PubMedBERT and the other leveraging our novel Entity-aware Masking for Biomedical Relation Extraction (EMBRE) method. Both models adhered to the settings provided by the BioRED official startup code. The vanilla PubMedBERT model, pretrained on literature from PubMed, serves as a baseline. Our EMBRE method [33] introduces an innovative entity-aware masking pretraining strategy aimed at enhancing the representation of entities, thereby improving performance in biomedical relation extraction. Specifically, during pretraining with the BioRED corpus, named entities are masked, and the model is tasked with identifying both the identifier and the type of the masked entity.
The performance of the vanilla PubMedBERT model was quantified, yielding a Precision of approximately 0.402, Recall of 0.115, and an F1-score of 0.179 for the task of entity pair extraction. In comparison, our proposed EMBRE method achieved a Precision of approximately 0.234, Recall of 0.217, and an F1-score of 0.225. This represents a significant improvement over the vanilla PubMedBERT model, particularly when considering the F1-score as the primary metric for comparison. The increase in F1-score indicates the effectiveness of our entity-aware masking pretraining strategy in bolstering the model’s ability to accurately extract and identify relations between biomedical entities. The results of the EMBRE method demonstrate the potential of tailored pretraining strategies to address specific challenges within the biomedical domain.
Results
We received 56 submissions from a total of 14 teams. The participating teams represent seven nations from Europe, Asia, Australia, and North America. Two teams were from industry, with the remainder from universities. The teams reported sizes of two to seven (average four), typically with backgrounds in NLP, machine learning, information retrieval, and/or computer science.
Team results
We report the performance of the benchmarking systems in Tables 2 and 3. The highest performing system is BioREX and we have highlighted its performance. In addition, we note that the GPT performance, while impressive, is lower than BioREX. Please note that The BioREx method cannot predict the novelty.
The evaluation results for all official submissions for Subtask 1 are summarized in Fig. 6, and the results for Subtask 2 are summarized in Fig. 7. The figures show the F-scores evaluation results for all official submissions for each subtask as well as the median lines for each evaluation: (i) entity pair, (ii) entity pair + relationship types, (iii) entity pair + novelty, and (iv) all of the above. Each submission is labeled with the team number and the number of the submission. Each team was allowed up to five submissions for each subtask. The ranking of the submissions correspond to the first evaluation, identifying the correct entity pairs. However, notice that the rankings of the different evaluation measures are different demonstrating that we do not have one clear winner. Finally, it is important to note that all teams reported increased F-scores in their unofficial submitted runs, which indicates that there is a lot of room for improvement for this task.
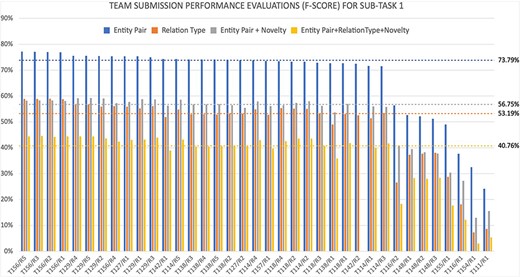
Summary of all official system submissions for Subtask 1, Shown in the x-axis is the team number followed by the submission run number- and the y-axis shows four F-score evaluations for the four evaluation measures: (i) on recognizing the correct entity pair, (ii) on recognizing the correct relationship type, (iii) on recognizing the novelty of a relationship providing the correct relation pair is identified, and (iv) on recognizing the novelty of a relationship when the correct relation pair and the relation type is identified. The median levels are marked for each evaluation.
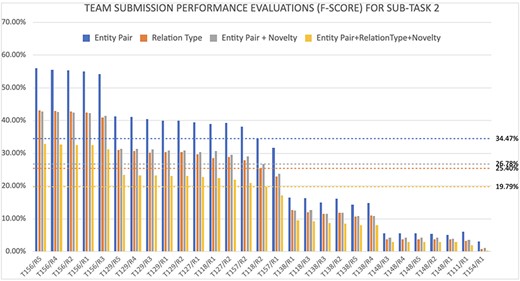
Summary of all official system submissions for Subtask 2, the x-axis lists the team number followed by the submission run number and the y-axis shows for each submission four F-score evaluations for the four evaluation measures: (i) on recognizing the correct entity pair, (ii) on recognizing the correct relationship type, (iii) on recognizing the novelty of a relationship providing the correct relation pair is identified, and (iv) on recognizing the novelty of a relationship when the correct relation pair and the relation type is identified. The median levels are marked for each evaluation.
For Subtask 2, the evaluation of the end-to-end systems depended on highly accurate predictions of the entities and their corresponding database identifiers. We noticed that teams with higher resources and those that were able to achieve higher NER predictions were able to report better relationship identification scores.
When we look at the methods and resources utilized by the participating teams on this task, we notice that most teams relied on BERT-based models such as PubMedBERT, BioBERT, etc. For Subtask 2, since most teams did not develop their in-house NER systems, we noticed that the majority relied on PubTator API or other tools to retrieve the predicted entities. NLTK and Spacy were popular tools for data preprocessing. We also noticed the use of additional resources such as CRAFT, AIONER, NCBI Entrez, and OMIM, as well as the incorporation of GPT models in different capacities. We saw the use of large learning models for fine-tuning results and for data augmentation. Several teams used tools such as rhw, or nlpaug, to rewrite the input abstracts for data augmentation to their input models. Notably, all top performing teams relied on ensemble models.
Discussion and conclusions
Through the BioRED track at BioCreative VIII, we aimed to foster the development of largescale automated methods that could handle the task of relationship extraction (i) at the document level, (ii) among multiple entity types, and (iii) on a real-life setting, where we are faced with new, previously unseen research topics that might contain previously unseen entities.
The submitted systems needed to perform all those tasks successfully, meaning that these systems needed to be capable of multiple-type named entity recognition, and multiple entity type relation extraction, semantic type relation recognition, and novelty identification. Most submitted systems were built as multitask systems, interweaving the results of individual task systems and combining these results via a reliable statistical approach tuned according to the training data. Most systems demonstrated clever usage of the large language models to augment the training data by syphoning LLM produced alternative texts for annotated relation in the training set, and the results showed that these systems had an advantage over the other systems. For Subtask 2, we noticed that the submitted systems’ success was dependent on highly accurate predictions of named entity recognition systems. This demonstrates that the unambiguous entity recognition of diseases, genes, chemicals, and variants, the recognition of which also depends on the accurate identification of species, is a crucial step in the advancement of biomedical natural language understanding.
The BioRED-BC8 corpus consisted of 1000 PubMed articles manually annotated for entities, pairwise relations, semantic types of those relations, and their novelty factor, distinguishing between novel contributions and background knowledge. While this resource adequately responded to the requirements of the BioRED track challenge, and faithfully simulates a real-life task setting, the dataset only promised to represent a PubMed article sample that is rich in bioentities, and rich in relations between relevant bioentities from recent published literature. However, in such a scenario, the related entity pairs and their corresponding semantic types could not be equally represented, because of their expected occurrence in the literature. For example, the BioRED-BC8 corpus contains more <gene, gene>, <gene, chemical>, <disease, chemical>, <gene, disease>, and <variant, disease> relations, when compared to <chemical, variant>, <variant, variant>, or <chemical, chemical> relations. Similarly, the dataset contains more Association, Positive Correlation, and Negative Correlation semantic types compared to Cotreatment, Drug Interaction, Conversion, Comparison, and Bind relation types. As such, we expect that systems that rely mainly on the BioRED-BC8 dataset may not be sufficiently sensitive in predicting the lesser represented types of relations.
We also analyzed all predictions submitted by all systems, and identified those relations that were missed by the majority of the submissions. We reviewed these data at the 50% and 75% levels, meaning all relations which were missed by at least 50% or at least 75% of the submitted runs. We find that, out of 5210 annotated relations in 400 articles, at least 50% of the BioCreative VIII participating systems had trouble identifying 1208 (23.2%) of them distributed in 257 articles, and at least 75% of the participating systems had trouble identifying 668 (12.8%) relations distributed in 170 articles. In Fig. 8, we chart a detailed distribution of these error types, and point out that the majority of the missed relations were between <disease, chemical>, <gene, disease>, and <variant, disease > . When we look at the types of these relations, almost 50% are type association, 30% positive correlation, and 16% negative correlation. In addition, we manually reviewed these missed relations, and we noticed that 26.8% of them consisted of entity pairs that were mentioned in different sentences, and 52% of them contained one entity mentioned only once in the abstract, suggesting that future systems working in relation extraction need to account for the fact that, contrary to the long-held belief, semantically important entities are not necessarily mentioned multiple times in an article abstract.
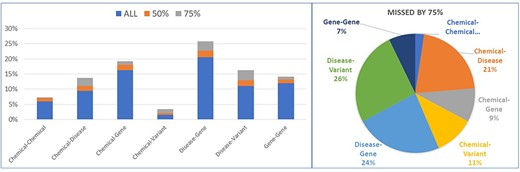
Error analysis for relation identification from all BioCreative VIII submitted systems. The graph on the left catalogues the distribution of the missed relation pair types for the relations that were missed by at least 50% and then 75% of all submitted systems (at least 28 and 42 of the 56 systems did not predict this relation), in context to all the other relations of the same type that were predicted correctly. The graph on the right shows these relations as a composition of all the errors.
Finally, we reviewed some of the submitted results to see if there are additional particular challenges that we could direct future systems to focus on. We selected all articles in the testing dataset on the topic of COVID-19, which was a topic unseen in the training data, and reviewed all submitted results for these articles. While we were very encouraged to see that for more than 80% of these articles there were systems reporting an F-score of 70% or higher, we noticed that systems still have difficulties when the entities are not expressed in the same sentence and especially when they are positioned far apart in the document (Fig. 9). The more coreferences, and the more difficult the language in the article, the harder it is for automated system to find the right relationship.

An example of a difficult article. The relations annotated in this text demonstrate a positive correlation between three different variants and a disease (COVID-19). Interestingly, COVID-19 is mentioned only once, in the first word of the abstract. While the species SARS-CoV-2 is mentioned twice and it is clear that the variants of the spike protein are of the same species, because the disease name and variants do not cooccurr in the same sentence, none of the submitted systems were able to predict these relations. Please note that all the depicted systems were able to predict the relation between two proteins cooccurring in the same sentence.
Despite these difficulties, the BioRED track at BioCreative VIII attracted a wide participation and based on the activity on the BioRED evaluation leaderboard at the codalab location https://codalab.lisn.upsaclay.fr/competitions/16381, it continues to receive even wider interest. We believe that the BioRED dataset will be widely used as a benchmark to evaluate better systems that are better able at handling these challenges.
Funding
This research was supported by the NIH Intramural Research Program, National Library of Medicine. It was also supported by the Fundamental Research Funds for the Central Universities [DUT23RC(3)014 to L.L.]. T.A. was funded by FCT (Foundation for Science and Technology) under the grant 2020.05784.BD. R.A.A.J. was funded by FCT (Foundation for Science and Technology) within project DSAIPA/AI/0088/2020. Y.Y.H. was funded by grant number NSTC 112–2321-B-006-008. The work of Team 154 (lasigeBioTM) was supported by Fundação para a Ciência e a Tecnologia (FCT) through funding of LASIGE Computer Science and Engineering Research Centre (LASIGE) Research Unit (UIDB/00408/2020 and UIDP/00408/2020) and FCT and FSE through funding of PhD Scholarship (UI/BD/153730/2022) attributed to SIRC. The work on the Team 142’s models and manuscript preparation was conducted at Kazan Federal University and supported by the Russian Science Foundation (grant number 23–11-00358).
Data Availability
The BioRED track dataset and other challenge materials are available at https://ftp.ncbi.nlm.nih.gov/pub/lu/BC8-BioRED-track/. The BioRED evaluation leaderboard is available at https://codalab.lisn.upsaclay.fr/competitions/16381.
Conflict of interest
None declared.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}