





Abstract
Tens of thousands of influenza sequences are deposited into the GenBank database each year. The software tool FLu ANnotation tool (FLAN) has been used by GenBank since 2007 to validate and annotate incoming influenza sequence submissions and has been publicly available as a webserver but not as a standalone tool. Viral Annotation DefineR (VADR) is a general sequence validation and annotation software package used by GenBank for norovirus, dengue virus and SARS-CoV-2 virus sequence processing that is available as a standalone tool. We have created VADR influenza models based on the FLAN reference sequences and adapted VADR to accurately annotate influenza sequences. VADR and FLAN show consistent results on the vast majority of influenza sequences, and when they disagree, VADR is usually correct. VADR can also accurately process influenza D sequences as well as influenza A H17, H18, H19, N10 and N11 subtype sequences, which FLAN cannot. VADR 1.6.3 and the associated influenza models are now freely available for users to download and use.
Database URL:https://bitbucket.org/nawrockie/vadr-models-flu.
Introduction
The World Health Organization estimates that influenza virus infects 1 billion people worldwide each year, leading to between 290 000 and 650 000 deaths (2). Influenza viruses are segmented negative-sense RNA viruses belonging to the family Orthomyxoviridae, of which four genera, commonly referred to as Types A, B, C and D, infect vertebrates. The vast majority of human illness from influenza is caused by Type A which has caused four pandemics since 1900 (1918, 1957, 1968 and 2009) (12, 25) and is also widespread in birds (17) and pigs as well as other mammals. Types B and C also infect humans, and Type D is mostly found in cows and pigs. Influenza A has eight segments and is further classified into subtypes (e.g. H5N1) based on the hemagglutinin and neuraminidase glycoproteins encoded on segments 4 and 6, respectively.
Large-scale genomic sequencing of influenza has been employed for nearly 20 years to help understand and track the prevalence, evolution and antiviral resistance of the virus (9, 14, 22, 28). The number of available sequences has grown steadily since 2000, and currently more than one million genomic (nucleotide) influenza sequences exist in the public databases GenBank, European Nucleotide Archive (ENA) (6) and DNA Databank of Japan (DDBJ) (24), which comprise the International Nucleotide Sequence Database Collaboration (INSDC) (4) (Figure 1). While all three INSDC databases share and host the same data, sequences are initially submitted to, and quality checked by, only one of the databases. More than 90% of the influenza sequences in INSDC databases were submitted to GenBank, which is maintained by the National Center for Biotechnology Information (NCBI) at the National Library of Medicine (NLM) in the USA. In the past 5 years, roughly 50 000 influenza A sequences per year were deposited in GenBank. The volume of influenza B sequences has leveled off in recent years, and the volume of influenza C and D sequences has always been relatively low, never reaching 1000 in a year. In addition to hosting the sequence information, NCBI provides the NCBI Virus resource (10) to facilitate and simplify access to it.
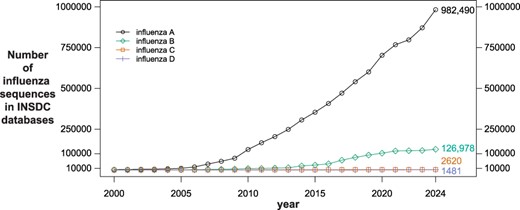
Number of influenza sequences in International Nucleotide Sequence Database Collaboration databases since 2000 (sequence counts were obtained using the National Center for Biotechnology Information Virus Data Hub filtering by release date; total counts as of December 31, 2023 are shown next to the 2024 datapoint; National Center for Biotechnology Information taxonomy ids: 11320 (influenza A); 11520 (influenza B); 11552 (influenza C); 1511084 (influenza D)).
FLAN is a tool for influenza genome annotation
Since 2007, NCBI has used an internally developed software program called FLu ANnotation tool (FLAN) (5) for validation and annotation of influenza sequences. FLAN has been used in two main contexts: for screening incoming influenza sequence submissions to the GenBank database and as a publicly available webserver that allows users to validate and annotate their own data. As a screening tool for GenBank, FLAN has been used since 2017 to automatically process sequence submissions of influenza A, B, or C sequences. Submissions with zero FLAN errors are automatically deposited into GenBank without any manual processing. Submissions with at least one sequence with one or more errors are not deposited. Instead, detailed error reports are either automatically sent to the submitters or reviewed by expert NCBI curators for quality, depending on the specific nature of the errors. Prior to 2017, FLAN was used manually to check influenza sequences submitted to GenBank.
FLAN proceeds through multiple steps to classify, validate and annotate input sequences. First, the “blastn” program from the BLAST package (3) is used to compare the input nucleotide sequence against a reference database of influenza A, B and C nucleotide sequences and classify each sequence type (A, B or C) and segment. For influenza A segment 4 and 6 sequences, the subtype of the hemagglutinin and neuraminidase segments is also determined. The FLAN reference database contains a single reference nucleotide sequence for each type and segment and subtype for hemagglutinin (H1 to H16) and neuraminidase (N1 to N10) influenza A segments.
Following classification, each sequence is then aligned to the corresponding reference protein set of one or more proteins for the classified type/segment/subtype using the ProSplign program for nucleotide to protein alignment (1). ProSplign is capable of detecting frameshifts and handling introns. FLAN detects a dozen types of errors in input sequences listed in Table 1. An error-free alignment is the one that extends to the N and C termini of the reference protein sequence (or to the end of the input sequence if it is incomplete at the 5’ and/or 3’ end) with valid start and stop codons at the ends and zero in-frame internal stop codons. Furthermore, there must be zero frameshifts, and for proteins with mature peptides, those peptides must be properly arranged (adjacent peptides must have zero nucleotides between them and not overlap). FLAN uses the positional information from the ProSplign alignment to determine nucleotide boundary positions for coding sequences and signal and mature peptides for Type A segment 4 sequences.
Mapping of FLAN and VADR errors and number of instances in the combined training and testing data sets.
| #cons- | #FLAN- | #VADR- | ||||
|---|---|---|---|---|---|---|
| FLAN error | VADR error(s) and (alert code(s)) | #FLAN | #VADR | istent | unique | unique |
| The coding region of (mature | POSSIBLE_FRAMESHIFT_- | 285 | 363 | 265 | 20 | 98 |
| peptide) X has a frameshift | HIGH_CONF (fsthicft, fsthicfi) | |||||
| The coding region of X has | CDS_HAS_STOP_CODON | 82 | 249 | 72 | 10 | 177 |
| stop codon inside exon | (cdsstopn) | |||||
| This sequence does not have | NO_FEATURES_ANNOTATED | 2 | 0 | 0 | 2 | 0 |
| coding capacity | (noftrann, noftrant) | |||||
| Contains extra X nts upstream | EXTRA_SEQUENCE_START | 232 | 166 | 144 | 88 | 22 |
| the consensus 5’ end sequence | (extrant5) | |||||
| Contains extra X nts downstream | EXTRA_SEQUENCE_END | 565 | 156 | 136 | 429 | 20 |
| the consensus 3’ end sequence | (extrant3) | |||||
| Probable mutation at the Start of | MUTATION_AT_START | 44 | 9 | 6 | 38 | 3 |
| protX | (mutstart) | |||||
| Probable mutation at the End of | MUTATION_AT_END | 57 | 49 | 19 | 38 | 30 |
| protX | (mutendcd, mutendns, mutendex) | |||||
| No blast hits found | NO_ANNOTATION (noannotn) | 0 | 0 | 0 | 0 | 0 |
| Mature peptides (X) and (Y) | PEPTIDE_ADJACENCY_- | 26 | 0 | 0 | 26 | 0 |
| have overlap/are separated | PROBLEM (pepadjcy) | |||||
| The input sequence is the | REVCOMPLEM | 0 | 0 | 0 | 0 | 0 |
| reverse complementary strand | (revcompl) | |||||
| of the coding sequence | ||||||
| Expected splice site consensus | MUTATION_AT_SPLICE_SITE | 0 | 16 | 0 | 0 | 16 |
| sequence not found for protein X | (mutspst5,mutspst3) | |||||
| Wrong exon number X for | – | 4 | – | – | 4 | – |
| Segment Y protein Z | ||||||
| Any | Any | 1297 | 1008 | 642 | 655 | 366 |
Counts are of number of sequence/feature pairs with at least one of the FLAN or VADR error/alert. Some sequence/feature pairs may have multiple errors for the same feature, but these are only counted once. Any mapped FLAN and VADR errors are considered consistent if they occur for the same sequence/feature pair. All FLAN errors that cause a sequence to fail (with exceptions detailed in the text) are listed, but not all VADR fatal alerts are.
Although FLAN has been in routine use at NCBI for more than 15 years, it is difficult to maintain and expand for novel influenza sequence diversity. Additionally, the program is not portable or available as a standalone program and users may only access it via its webserver interface or by submitting sequences to GenBank, such that local execution is not possible and high-throughput use is difficult.
VADR is a general tool for viral genome annotation
Viral Annotation DefineR (VADR) is a software package also developed at NCBI for validating and annotating viral sequences and protein-coding sequences (23). Not only it is written in Perl, but it also relies on and calls programs from other software such as Infernal (19), BLAST (3), FASTA (21) and minimap2 (15, 16). VADR is a general tool that includes a program called “v-build.pl” for creating new models for a virus based on existing GenBank or RefSeq records that include information on coding sequence (CDS), gene, mature peptide and structural RNA features. The “v-annotate.pl” program then uses a library of those models to classify input sequences to their best-matching model and validate and annotate features based on an alignment to that model. Finally, the protein coding potential of each predicted coding sequence is validated using “blastx” with a library of reference protein sequences. During this analysis, different types of unexpected features, such as early stop codons and potential frameshifts identified from the nucleotide alignment (not at the protein level) can be identified and reported in the form of “alerts” to the user. A subset of alerts are “fatal” and cause a sequence to “fail” validation.
VADR is used to automatically screen and validate incoming GenBank submissions of norovirus, dengue virus, SARS-CoV-2 and metazoan COX1 protein coding mitochondrial sequences in a similar way to how FLAN is used for influenza sequence submissions. Sequence submissions with zero fatal alerts are automatically deposited into GenBank. For submissions with one or more fatal alerts, a detailed error report is sent to the submitter or prepared for a GenBank curator to review. The scope of VADR alerts overlaps heavily with that of FLAN errors (Table 1).
In contrast to FLAN, VADR is actively maintained and developed and is available as a standalone program so that users can run it locally. We describe here our effort to make VADR useful for influenza sequence analysis, by building new models based on the FLAN reference sequences.
Materials and methods
Creation of VADR influenza model libraries
We created influenza models for VADR based on the existing FLAN models and then compared the performance of VADR and FLAN at validating and annotating existing influenza sequences. The nucleotide and protein reference sequence sets that FLAN uses are available online at (https://ftp.ncbi.nlm.nih.gov/genomes/INFLUENZA/ANNOTATION/), but the specific accessions of those sequences are absent from those files and from the FLAN publication (5). The first step toward making VADR influenza models was determining the INSDC accessions that the FLAN reference sequences map to, so that we could build VADR models from those accessions and those models would include the sequence annotation information from GenBank, ENA or DDBJ.
The FLAN reference sequence set includes 46 nucleotide sequences, 96 protein sequences and 72 mature peptide sequences. Of the 46 nucleotide sequences, 45 have at least one identically matching sequence in INSDC, and the remaining sequence is a subsequence of an existing INSDC sequence. Of the 96 protein sequences, 69 matched identically to at least one INSDC sequence and 14 of the remaining 28 are an exact subsequence of at least one INSDC sequence. For the remaining 14, we determined the best matching INSDC sequence for each, defined as the sequence with the best “blastp” (3) score when searched against the non-redundant protein sequences set (‘nr’) database using the “blastp” webserver (https://blast.ncbi.nlm.nih.gov/Blast.cgi). The 72 mature peptide sequences are not relevant to VADR model building, so we did not attempt to map these to INSDC sequences. More details on the sequence mapping, including specific accessions, can be found in the freely available VADR influenza model data set.
A VADR model was created for each of the 46 INSDC-mapped nucleotide sequences using the “v-build.pl” program from VADR 1.6 with default parameters, and gene and CDS product names were modified to match FLAN. The models were combined to create a model library as explained in the VADR documentation. The VADR model library was modified by adding the mapped INSDC protein sequences to their corresponding models’ “blastx” protein libraries.
After building VADR models that matched the FLAN reference sets, we expanded them in several ways in an effort to improve their performance. As detailed later, we added eight additional protein sequences to the influenza A “blastx” libraries. We also added models for influenza D and for influenza A subtypes that were discovered after FLAN was developed and replaced five incomplete influenza C genome sequences used by FLAN with complete genome sequences from RefSeq. Specifically, we
added eight models for the novel H17/N10 subtypes (26), one per segment (accessions CY103881.1-CY103888.1)
added eight models for the novel H18/N11 subtypes (27), one per segment (accessions CY125942.1-CY125949.1)
added one model for the novel H19 subtype (8), segment 4 (accession ON637239.1).
replaced the five non-RefSeq influenza C models with RefSeq-based models (GN364866.1, GM968019.1, GM968018.1, GM968017.1 and GM968016.1 replaced with NC_006307.2, NC_006308.2, NC_006309.2, NC_006310.2 and NC_006312.2, respectively).
added seven RefSeq-based influenza D models (NC_036615.1–NC_036621.1).
For the 29 added or replaced models, the “v-build.pl” program from VADR 1.6 was used to create the models with default parameters using the indicated accessions.
We made changes to two of the VADR models to improve annotation on some sequences. Specifically, we rebuilt the covariance model (CM) file for the CY006079.1 type A segment 5 model using a two sequence alignment containing the original CY006079.1 sequence and a copy of it with an insertion of a single A nucleotide after position 1542. Similarly, we rebuilt the CM file for the CY005970.1 type A segment 4 model using a two sequence alignment containing the original CY005970.1 sequence and a copy of it with a substitution of the G nucleotide at position 1719 with an A. Using these new models reduces the number of spurious alerts related to stop codons. The changes were motivated by analysis of the VADR results on the training set sequences, and more details are available in the documentation included with the model files. Tables 2 and 3 include more details on the final set of VADR influenza models (version 1.6-2).
List of VADR and FLAN influenza A model reference sequences and attributes of associated proteins.
| Model | Model | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Type | Segment | Subtype | accession | length | CDS product | Gene | Intron | #proteins | #coords | #extra |
| A | 1 | – | CY002079.1 | 2341 | Polymerase PB2 | PB2 | No | 3 | 2 | – |
| A | 1 | – | CY103881.1 | 2338 | Polymerase PB2 | PB2 | No | 1 | 1 | – |
| A | 1 | – | CY125942.1 | 2338 | Polymerase PB2 | PB2 | No | 1 | 1 | – |
| A | 2 | – | CY003646.1 | 2341 | PB1-F2 protein | PB1-F2 | No | 14 | 12 | – |
| Polymerase PB1 | PB1 | No | 4 | 2 | 1 | |||||
| A | 2 | – | CY103882.1 | 2339 | Polymerase PB1 | PB1 | No | 1 | 1 | – |
| A | 2 | – | CY125943.1 | 2339 | Polymerase PB1 | PB1 | No | 1 | 1 | – |
| A | 3 | – | CY003645.1 | 2233 | PA-X protein | PA-X | Yes | 4 | 2 | – |
| Polymerase PA | PA | No | 3 | 1 | 1 | |||||
| A | 3 | – | CY103883.1 | 2216 | Polymerase PA | PA | No | 1 | 1 | – |
| A | 3 | – | CY125944.1 | 2216 | Polymerase PA | PA | No | 1 | 1 | – |
| A | 4 | H1 | CY000449.2 | 1778 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H2 | CY003907.1 | 1773 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H3 | CY002000.1 | 1762 | Hemagglutinin | HA | No | 4 | 1 | – |
| A | 4 | H4 | CY004847.1 | 1738 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H5 | DQ864721.1 | 1780 | Hemagglutinin | HA | No | 4 | 1 | – |
| A | 4 | H6 | DQ376635.1 | 1747 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H7 | CY006037.1 | 1732 | Hemagglutinin | HA | No | 7 | 1 | – |
| A | 4 | H8 | CY005970.1 | 1744 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H9 | CY004642.1 | 1742 | Hemagglutinin | HA | No | 3 | 1 | 1 |
| A | 4 | H10 | CY006001.1 | 1728 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H11 | CY006005.1 | 1760 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H12 | CY006008.1 | 1737 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H13 | CY005979.1 | 1768 | Hemagglutinin | HA | No | 2 | 1 | – |
| A | 4 | H14 | M35997.1 | 1749 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 4 | H15 | CY006034.1 | 1763 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 4 | H16 | AY684891.1 | 1760 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 4 | H17 | CY103884.1 | 1784 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 4 | H18 | CY125945.1 | 1771 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 4 | H19 | ON637239.1 | 1686 | Hemagglutinin | HA | No | 1 | 1 | – |
| A | 5 | – | CY006079.1 | 1565 | Nucleocapsid protein | NP | No | 2 | 1 | – |
| A | 5 | – | CY103885.1 | 1558 | Nucleocapsid protein | NP | No | 1 | 1 | – |
| A | 5 | – | CY125946.1 | 1557 | Nucleocapsid protein | NP | No | 1 | 1 | – |
| A | 6 | N1 | CY002538.1 | 1463 | Neuraminidase | NA | No | 3 | 1 | 1 |
| A | 6 | N2 | CY002010.1 | 1467 | Neuraminidase | NA | No | 4 | 2 | 1 |
| A | 6 | N3 | CY005890.1 | 1453 | Neuraminidase | NA | No | 2 | 1 | – |
| A | 6 | N4 | CY005359.1 | 1463 | Neuraminidase | NA | No | 1 | 1 | – |
| A | 6 | N5 | CY004429.1 | 1470 | Neuraminidase | NA | No | 2 | 1 | – |
| A | 6 | N6 | CY005641.1 | 1465 | Neuraminidase | NA | No | 2 | 1 | – |
| A | 6 | N7 | CY004435.1 | 1462 | Neuraminidase | NA | No | 1 | 1 | – |
| A | 6 | N8 | CY004056.1 | 1461 | Neuraminidase | NA | No | 1 | 1 | – |
| A | 6 | N9 | CY004131.1 | 1460 | Neuraminidase | NA | No | 2 | 1 | – |
| A | 6 | N10 | CY103886.1 | 1390 | Neuraminidase | NA | No | 1 | 1 | – |
| A | 6 | N11 | CY125947.1 | 1426 | Neuraminidase-like protein | NA | No | 1 | 1 | – |
| A | 7 | – | CY002009.1 | 1027 | Matrix protein 1 | M1 | No | 2 | 1 | – |
| Matrix protein 2 | M2 | Yes | 3 | 2 | – | |||||
| A | 7 | – | CY103887.1 | 1027 | Matrix protein 1 | M1 | No | 1 | 1 | – |
| Matrix protein 2 | M2 | Yes | 1 | 1 | – | |||||
| A | 7 | – | CY125948.1 | 1027 | Matrix protein 1 | M1 | No | 1 | 1 | – |
| Matrix protein 2 | M2 | Yes | 1 | 1 | – | |||||
| A | 8 | – | CY002284.1 | 890 | Nonstructural protein 1 | NS1 | No | 14 | 9 | 3 |
| Nuclear export protein | NEP | Yes | 2 | 1 | – | |||||
| A | 8 | – | CY103888.1 | 895 | Nonstructural protein 1 | NS1 | No | 1 | 1 | – |
| Nuclear export protein | NEP | Yes | 1 | 1 | – | |||||
| A | 8 | – | CY125949.1 | 895 | Nonstructural protein 1 | NS1 | No | 1 | 1 | – |
| Nuclear export protein | NEP | Yes | 1 | 1 | – |
The “#coords” column indicates the number of distinct pairs of start and stop genome nucleotide coordinates for all proteins in the set. The “# proteins” column indicates the number of proteins in the set, and the “#extra” column indicates the number of additional proteins added to the VADR protein set not present in the FLAN set based on analysis of training set results. For CDS that have italicized “CDS product” and “gene” names, FLAN errors are converted to warnings and VADR converts them to “misc_feature” features if they have certain usually fatal alerts, instead of failing the sequence. Bold model accessions indicate models without an analog in FLAN.
List of VADR and FLAN influenza B, C and D model reference sequences and attributes of associated proteins.
| Model | Model | |||||||
|---|---|---|---|---|---|---|---|---|
| Type | Segment | accession | length | CDS product | Gene | Intron | #proteins | #coords |
| B | 1 | EF626642.1 | 2369 | Polymerase PB1 | PB1 | No | 2 | 1 |
| B | 2 | AY504599.1 | 2396 | Polymerase PB2 | PB2 | No | 2 | 1 |
| B | 3 | EF626633.1 | 2305 | Polymerase PA | PA | No | 2 | 1 |
| B | 4 | AF387493.1 | 1882 | Hemagglutinin | HA | No | 4 | 1 |
| B | 5 | EF626631.1 | 1844 | Nucleoprotein | NP | No | 2 | 1 |
| B | 6 | AY191501.1 | 1557 | NB protein | NB | No | 1 | 1 |
| Neuraminidase | NA | No | 3 | 1 | ||||
| B | 7 | AY504605.1 | 1190 | BM2 protein | BM2 | No | 4 | 2 |
| Matrix protein 1 | M1 | No | 1 | 1 | ||||
| B | 8 | AY504614.1 | 1097 | Nonstructural protein 1 | NS1 | No | 4 | 1 |
| Nuclear export protein | NEP | Yes | 3 | 1 | ||||
| C | 1 | NC_006307.2 | 2365 | Polymerase PB2 | PB2 | No | 1 | 1 |
| C | 2 | NC_006308.2 | 2363 | Polymerase PB1 | PB1 | No | 1 | 1 |
| C | 3 | NC_006309.2 | 2183 | Polymerase P3 | P3 | No | 1 | 1 |
| C | 4 | NC_006310.2 | 2073 | Hemagglutinin-esterase | HE | No | 1 | 1 |
| C | 5 | NC_006311.2 | 1807 | Nucleoprotein | NP | No | 1 | 1 |
| C | 6 | NC_006312.2 | 1180 | CM2 protein | CM2 | No | 1 | 1 |
| Matrix protein 1 | M1 | Yes | 1 | 1 | ||||
| C | 7 | NC_006306.2 | 935 | Nonstructural protein 1 | NS1 | No | 1 | 1 |
| Nonstructural protein 2 | NEP | Yes | 1 | 1 | ||||
| D | 1 | NC_036616.1 | 2364 | Polymerase PB2 | PB2 | No | 1 | 1 |
| D | 2 | NC_036615.1 | 2330 | Polymerase PB1 | PB1 | No | 1 | 1 |
| D | 3 | NC_036619.1 | 2195 | Polymerase 3 | P3 | No | 1 | 1 |
| D | 4 | NC_036618.1 | 2049 | Hemagglutinin-esterase precursor | HEF | No | 1 | 1 |
| D | 5 | NC_036617.1 | 1775 | Nucleoprotein | NP | No | 1 | 1 |
| D | 6 | NC_036620.1 | 1219 | P42 | P42 | No | 1 | 1 |
| D | 7 | NC_036621.1 | 868 | Nonstructural protein 1 | NS1 | No | 1 | 1 |
| Nonstructural protein 2 | NS2 | Yes | 1 | 1 |
The “#coords” column indicates the number of distinct pairs of start and stop genome nucleotide coordinates for all proteins in the set. The “# proteins” column indicates the number of proteins in the set. Bold model accessions indicate models without an analog in FLAN. Italicized model accessions indicate models for which VADR uses a different accession than FLAN.
Construction of training and testing sequence sets
To compare the performance of VADR and FLAN at validating and annotating influenza sequences, we constructed multiple disjoint sequence sets for training and testing. The training sets are made up of 10 000 influenza A sequences, 1000 influenza B sequences and 500 influenza C sequences each from GenBank and from ENA or DDBJ (23 000 sequences in total, Table 4), which are 60 nucleotides (nt) or longer and are not in the patent’ INSDC division. Separate sets were chosen from GenBank and ENA/DDBJ because the vast majority of GenBank influenza sequences submitted since 2007 have been screened with FLAN, whereas ENA and DDBJ do not use FLAN, so those sequences are not biased by having been checked with FLAN. The sequences were chosen randomly from all candidate sequences downloaded from the NCBI virus resource (https://www.ncbi.nlm.nih.gov/labs/virus/vssi/#/) with release date before 17 March 2023 (the date of our initial collection). We examined and compared FLAN and VADR results on the training sequences to help us improve VADR performance.
Comparison of pass/fail outcomes for FLAN and VADR on the influenza sequence training datasets.
| VADR | Fraction | #FLAN-pass | #FLAN-fail | ||||
|---|---|---|---|---|---|---|---|
| Data set | Number of sequences | model | pass both | #pass both | #fail both | VADR-fail | VADR-pass |
| Flu A GenBank | 10 000 | Final | 0.989 | 9891 | 54 | 50 | 5 |
| FLAN | 0.986 | 9859 | 54 | 82 | 5 | ||
| FLAN-ntonly | 0.895 | 8951 | 58 | 990 | 1 | ||
| Flu A ENA+DDBJ | 10 000 (4029+5971) | Final | 0.978 | 9784 | 156 | 50 | 10 |
| FLAN | 0.973 | 9726 | 156 | 108 | 10 | ||
| FLAN-ntonly | 0.923 | 9230 | 156 | 604 | 10 | ||
| Flu B GenBank | 1000 | Final | 0.999 | 999 | 0 | 0 | 1 |
| FLAN | 0.999 | 999 | 0 | 0 | 1 | ||
| FLAN-ntonly | 0.944 | 944 | 0 | 55 | 1 | ||
| Flu B ENA+DDBJ | 1000 (260+740) | Final | 0.981 | 981 | 4 | 1 | 14 |
| FLAN | 0.981 | 981 | 4 | 1 | 14 | ||
| FLAN-ntonly | 0.974 | 974 | 4 | 8 | 14 | ||
| Flu C GenBank | 500 | Final | 0.818 | 409 | 1 | 0 | 90 |
| FLAN | 0.818 | 409 | 90 | 0 | 1 | ||
| FLAN-ntonly | 0.818 | 409 | 90 | 0 | 1 | ||
| Flu C ENA+DDBJ | 500 (5+495) | Final | 0.720 | 360 | 0 | 0 | 140 |
| FLAN | 0.720 | 360 | 136 | 0 | 4 | ||
| FLAN-ntonly | 0.720 | 360 | 136 | 0 | 4 | ||
| Total | 23 000 | Final | 0.975 | 22 424 | 215 | 101 | 260 |
| FLAN | 0.971 | 22 334 | 440 | 191 | 35 | ||
| FLAN-ntonly | 0.907 | 20 868 | 444 | 1657 | 31 |
For ENA+DDBJ data sets, the numbers of ENA and DDBJ sequences in the set are indicated in parantheses in “Number of sequences” column, ENA listed first and DDBJ listed second.
We constructed additional sets of testing sequences that we did not utilize until after the VADR improvements based on the training set analysis were complete to see if the VADR performance on the training sets extended to other sequences. The test sets were constructed similarly to the training sets, again not only from both GenBank and ENA or DDBJ but also from two date ranges: up to 17 March 2023, the date of initial collection of the training sets, and between 18 March 2023 and 30 November 2023. Testing on the more current sequences checked performance on potentially novel sequence diversity not present in the other sequences. In total, there were 12 sets of test sequences, one for each combination of the three possible influenza types, two possible databases and two possible date ranges, with a combined 35 555 sequences. The specific numbers in each of the 12 sets are shown in Table 5. Some test sets were smaller than the corresponding training sets if not enough qualifying sequences existed to match the training set size (e.g. only 15 GenBank current influenza C test sequences compared with 500 GenBank influenza C training sequences). The test sequences were constructed such that there were zero sequences in common with the training sets.
Comparison of pass/fail outcomes for FLAN and VADR on the influenza sequence testing datasets.
| Fraction | #FLAN-pass | #FLAN-fail | |||||
|---|---|---|---|---|---|---|---|
| Data set | Release date | Number of sequences | Pass both | #pass both | #fail both | VADR-fail | VADR-pass |
| Flu A GenBank | Before 18 March 2023 | 10 000 | 0.992 | 9915 | 50 | 31 | 4 |
| After 17 March 2023 | 10 000 | 0.998 | 9983 | 0 | 17 | 0 | |
| Flu A ENA+DDBJ | Before 18 March 2023 | 10 000 (3965 + 6035) | 0.979 | 9793 | 156 | 46 | 5 |
| After 17 March 2023 | 2404 (2202 + 202) | 0.939 | 2258 | 123 | 10 | 13 | |
| Flu B GenBank | Before 18 March 2023 | 1000 | 0.996 | 996 | 0 | 4 | 0 |
| After 17 March 2023 | 1000 | 1.000 | 1000 | 0 | 0 | 0 | |
| Flu B ENA+DDBJ | Before 18 March 2023 | 391 (106 + 285) | 0.972 | 380 | 1 | 0 | 10 |
| After 17 March 2023 | 99 (99 + 0) | 0.990 | 98 | 0 | 0 | 1 | |
| Flu C GenBank | Before 18 March 2023 | 16 | 0.875 | 14 | 0 | 0 | 2 |
| After 17 March 2023 | 15 | 1.000 | 15 | 0 | 0 | 0 | |
| Flu C ENA+DDBJ | Before 18 March 2023 | 500 (2 + 498) | 0.732 | 366 | 1 | 0 | 133 |
| After 17 March 2023 | 130 (0 + 130) | 0.400 | 52 | 0 | 0 | 78 | |
| Total | Before 18 March 2023 | 21 907 | 0.980 | 21 464 | 208 | 81 | 154 |
| After 17 March 2023 | 13 648 | 0.982 | 13 406 | 123 | 27 | 92 |
For ENA+DDBJ data sets, the numbers of ENA and DDBJ sequences in the set are indicated in parantheses in “Number of sequences” column, ENA listed first and DDBJ listed second.
Defining pass/fail outcomes
To compare FLAN and VADR validation and annotation using our training and testing sets, we examined each program’s pass or fail outcome for each sequence. For VADR, a sequence fails if one or more fatal alerts are reported for it and passes otherwise. For FLAN, we defined a sequence as failing if one or more errors, denoted with a line starting with “ERROR” in the output feature table and listed in Table 1, are reported, with four exceptions. First, we ignored any errors for PB1-F2 (influenza A segment 2), PA-X (influenza A segment 3) or NB (influenza B segment 6) CDS features because Genbank curators routinely permit problems in these coding regions, annotating them as “misc_features” instead of CDS. This is because NB is nonessential for virus replication (11), PB1-F2 appears to be nonessential for viral viability (7) and PA-X has variable stop positions, which makes validation problematic (13). Ignoring errors for these CDS is consistent with our VADR tests, for which most fatal alerts in these CDS do not cause a sequence to fail due to a special setting in the VADR model files. Secondly, FLAN frameshift errors for mature peptides were ignored because every instance was accompanied by a frameshift error in the parent CDS (always the HA CDS) and because VADR only reports CDS frameshifts. Thirdly, the error “Input sequence is too short” was reported for 12 sequences in our training and testing sets of 200 nt or less [minimum length 61 nt (FJ222309.1) and maximum length 200 nt (FR687037.1)]; however, there were 68 other sequences of 200 nt or less that FLAN did not report this error for (e.g. AM922136.1, 63nt), and VADR does not have an analogous alert, so we decided to ignore this error. Finally, FLAN reported an error with the explanation: “Expected splice site consensus sequence not found for protein 2” for four total sequences (e.g HE584752.1) in our training and testing sets in which only one protein/CDS was annotated. Because it was not clear which protein the error referred to, we decided to ignore these four error instances.
Results and discussion
The VADR models built from the FLAN reference sequences were used to annotate the training sequence sets using the “v-annotate.pl” program, and the VADR results were compared with FLAN annotation results for the same sequences. Differences were manually examined to identify deficiencies in the VADR models, in the form of failing sequences that should pass, which were addressed by adding eight additional influenza A proteins to the VADR “blastx” libraries. For the CY002284.1 segment 8 model, three additional NS1 (nonstructural Protein 1) protein sequences were added (from nucleotide accessions KT370023.1, MT261562.1 and MT169392.1); for the CY002010.1 and CY002538.1 segment 6 models, the OP775156.1 and KT181405.1 NA (neuraminidase) proteins were added, respectively; for the CY004642.1 segment 4 model, the JF715039.1 HA (hemagglutinin) protein was added; for the CY003646.1 segment 2 model, the AB586849.1 PB1 (polymerase PB1) protein was added; for the CY003645.1 segment 3 model, the LC625435.1 PA (polymerase PA) protein was added.
Two significant modifications were made to the VADR software to better replicate the FLAN results. The first was the ability to detect and report extra sequence at the 5’ and 3’ ends of sequences with the extrant5 and extrant3 VADR alerts, analogous to the FLAN errors with the description “contains extra X nts upstream/downstream the consensus 5’/3’ end sequence.” The new extrant5 and extrant3 alerts are similar to the pre-existing lowsim5s and lowsim3s alerts for low similarity at the 5’ and 3’ ends, respectively, but extrant5 and extrant3 specifically pertain to the sequence that extends past the 5’ and 3’ termini of the reference model based on an alignment to the model, whereas lowsim5s and lowsim3s are reported when the ends of the input sequence do not match well to the model, regardless of whether the sequence alignment extends past the end of the model or ends internally as it would for partial genome sequences.
The second modification is the detection of canonical GT/AG donor/acceptor splice sites at the ends of intron sequences for the PA-X (A segment 3), M2 (A segment 7), M1 (C segment 6) and NEP (A and B segment 8, C and D segment 7) genes and the reporting of mutspst5 and mutspst3 alerts when those expected subsequences are missing in the input sequence. These new alerts are analogous to FLAN’s ‘Expected splice site consensus sequence not found for protein X’ errors. This capability did not yet exist because none of the other viruses or genes that VADR has been used for previously at NCBI include introns.
Table 4 summarizes the results of VADR and FLAN on the training sequence data sets. To demonstrate the impact of different aspects of the models, results for three different VADR model sets are shown: “FLAN-nt” are VADR models built exclusively from the FLAN reference nucleotide genomes and proteins from those genomes only; “FLAN” models additionally include the full FLAN reference protein sets, and “final” are the final set of VADR models. The final models include the eight additional proteins not present in the FLAN reference data sets specifically added to allow additional high-quality influenza A training sequences that would otherwise fail to pass VADR. The final set also includes the 29 alternative and novel VADR models not present in FLAN, as detailed in Materials and methods section.
Using the final models, VADR and FLAN give the same pass/fail designation for 97.8% or more of the sequences in each of the influenza A and B training data sets, indicating that VADR nearly always reproduces the pass/fail determination of FLAN for A and B sequences. Two hundred and ten type A and four type B sequences fail both programs. For influenza C, nearly all sequences either pass both programs or fail FLAN but pass VADR. In the set that fails FLAN but passes VADR, all but four of the 230 sequences fail FLAN due to the extra sequence at the 5’ or 3’ end which are not reported by VADR due to the alternative, longer influenza C models it uses. We did not test influenza D because FLAN does not include influenza D reference sequences.
The addition of the FLAN protein sets to the nucleotide only models (“FLAN” vs “FLAN-ntonly”) results in a large increase in the number of influenza A sequences that pass VADR, demonstrating the importance of multiple reference proteins for at least some of the influenza proteins. In the influenza A GenBank and non-GenBank sets (10 000 sequences each), 908 and 496 sequences, respectively, that failed VADR using the “FLAN-ntonly” models pass with the “FLAN” models. The corresponding increase in the influenza B data sets (1,000 sequences each) is 55 in the GenBank set and 7 in the non-GenBank set. For influenza C, these is no change.
Supplementing the “FLAN” influenza A models with additional proteins to the VADR protein libraries which are not present in the FLAN sets (“FLAN” vs “final”) results in a smaller increase in the number of influenza A sequences that pass VADR. Specifically, 32 and 58 sequences that previously failed VADR but passed FLAN now pass both programs in the GenBank and non-GenBank sets, respectively.
We also ran VADR and FLAN on our testing sets, which are disjoint from the training sets, to check how general the improvements made based on our analysis of the training set results would be on other sequences. The “final” model sets were already defined prior to our examination of the test set results, and no further changes were made based on their analysis. The test set results largely mirror the training set results, as shown in Table 5, which only shows results for the final model set, demonstrating that the models are likely not overtrained on the training data and should yield comparable results on new sequences. The high consistency between FLAN and VADR results on the new sequences collected since 17 March 2023 also suggests that VADR performance on sequences outside of the training set should largely be consistent with FLAN (Table 5).
Sequences with different VADR and FLAN pass/fail outcomes
We manually examined each sequence in the training and testing sets for which VADR and FLAN give different pass/fail outcomes. Next, we summarize our findings separately for each influenza type (A, B or C).
Differences for Type A sequences
There are 204 influenza A sequences in the training and testing sets that pass FLAN but fail VADR. Eighty five of these fail due to a possible frameshift (fsthicft and fsthicfi VADR alert codes), with nearly half (40) in the hemagglutinin CDS. A typical example is shown in Figure 2. Of these 85, 77 are terminal frameshifts near the beginning or end of the sequence and many are short frameshifts: 70 are 15 nt or less. Of the remaining 119 sequences, 44 fail VADR protein validation because no “blastx” alignment extends sufficiently close to the 5’ and 3’ ends of the predicted CDS (indf5pst and indf3pst, e.g. CY008965.1); 40 fail due to extra sequence detected at the 5’ or 3’ ends relative to the reference model sequence (extrant5, extrant3 alerts, e.g. OR675339.1); 11 fail due to large deletions (deletinp alerts, e.g. OY283585.1); eight fail due to possible mutations at splice donor or acceptor sites (mutspst5, mutspst3, e.g. AB513916.1); seven fail with low sequence similarity to the reference at the 5’ and/or 3’ ends of the sequence (lowsim5s, lowsim3s, e.g. OQ683476.1); five fail due to possible mutations in the stop codon (mutendex, mutendcd, mutendns, e.g. LC070034.1); one fails due to a mutation in a start codon (mutstart, e.g. MH283613.1), one fails due to low coverage resulting from a large stretch of N ambiguity characters of unexpected length (lowcovrg, CY095556.1), one fails due to a large insertion (insertnp, OQ722117.1) and one fails due to a large deletion (deletinp, OY282827.1).

Example potential frameshift detected by VADR but not by FLAN. VADR alignment of the first 99 nucleotides of CY009539.1 to the CY002079.1 influenza A segment 1 model reference sequence is shown with a single deletion with respect to the model sequence at model position 37, (highlighted); the polymerase PB2 CDS is encoded by positions 28–2307 of CY002079.1, so the first three nucleotides of the alignment correspond to the start codon; and VADR reports a potential frameshift (“fsthicft” alert) of all nucleotides (positions 10–2279) after the deletion; identical aligned nucleotides between the sequence and the model are indicated by * at the top of the alignment; some of the information reported in the VADR output file with suffix “.alt” is included below the alignment. FLAN passes CY009539.1 without a frameshift error or any other errors, possibly because the 9-nucleotide length prior to the frameshift is so short.
For some of the sequences that fail due to extra sequence alerts (extrant5 or extrant3), the additional sequence is actually a duplication of a sometimes reverse complemented region of the genome (e.g. LC168638.1), possibly due to an assembly error, which VADR reports as a separate dupregin and/or indfstrn alert. For some of the eight failures related to mutations at splice sites (mutspst5, mutspst3), the sequence fails because the intron for the M2 gene has been removed (e.g. EU384412.1, which matches best to the CY002009.1 model for Segment 7).
We have manually inspected all these VADR failures and believe that they are warranted in nearly all cases because they are situations that GenBank curators should manually investigate prior to the deposition of these sequences in GenBank. In a few cases, VADR simply gets it wrong and the sequences could reasonably pass without manual examination. An example is LC120391.1 which involves the deletion of a single G relative to the reference sequence CY000449.2, the first G in the subsequence TGAG within which TGA is the stop codon for the hemagglutinin CDS, but which leaves a valid TAG stop codon. VADR’s alignment-based stop-codon annotation balks at this deletion and reports a MUTATION_AT_END error (mutendex, mutendcd and unexleng alerts). This situation, which is fortunately rare in influenza sequences, highlights a specific limitation of VADR.
There are 37 influenza A sequences that pass VADR but fail FLAN in our training and testing sets. Twenty of these fail due to ambiguous nucleotides in the start and/or stop codons of CDS, which VADR is tolerant of (e.g. OX422492.1). For 11 sequences, FLAN reports a mutation in the start or stop codon (e.g. EU146784.1), but in all cases there is a valid start/stop codon that corresponds to at least one protein in the FLAN reference set (which is why these sequences do not fail VADR). A “wrong exon number” error is reported by FLAN for three sequences with more than 500 Ns (e.g OY284219.1). VADR’s method of replacing large stretches of Ns with reference sequence for validation and annotation purposes, and which does not have an analog in FLAN, seems to work well for these N-rich sequences. FLAN reports that two of the remaining three sequences (FJ222261.1 and FJ222309.1), both 61nt, do not have coding capacity, even though they encode 20 amino acid long partial NEP CDS. The final sequence (GU083607.1) fails due to extra nucleotides upstream of the consensus 5’ end sequence.
We have manually inspected these 37 sequences and have determined that in our opinion they should all pass. This does not mean that it is a significant problem that FLAN fails these sequences, as it is reasonable for some borderline sequences to fail so that expert curators can evaluate them before they are deposited into GenBank. However, it is reassuring to find that VADR is not allowing sequences to pass that are clearly problematic.
Differences for type B sequences
In the combined influenza B training and testing sets, there are 26 sequences that pass VADR but fail FLAN. For 17 of these FLAN reports, a probable mutation is at the start of the NEP gene (nonstructural Protein 2), but in all cases, the sequences begin toward the end of the first exon of NEP (e.g. AJ781277.1) or within its intron (e.g. AJ781285.1). Of the remaining nine sequences, eight are partial segment 7 sequences that end before the start of the BM2 CDS (e.g. HE803092.1), but FLAN reports a probable mutation at the start of the BM2 CDS. The final sequence (OY759012.1) fails due to probable mutation at the start and end due to ambiguities in the start and stop codons which VADR is tolerant of. We manually examined the VADR annotation for these 26 sequences and found it to be correct and confirmed that in our opinion, none of the errors were significant enough to prevent deposition in GenBank.
Of the five influenza B training and testing sequences that fail VADR but pass FLAN, four are due to possible frameshifts in segment 4 (e.g. KP461008.1) and one is due to 11 extra nucleotides at the 3’ end (MN086295.1). Three of the four frameshifts are due to a single nucleotide deletion at reference position 85 of the model sequence AF387493.1.
Differences for Type C sequences
For type C sequences, there are 443 sequences in the training and testing sets that pass VADR and fail FLAN. The vast majority of these (429) fail only due to FLAN errors about extra nucleotides upstream or downstream of the consensus 5’ or 3’ end sequence owing to extra sequence on the 5’ and/or 3’ ends (e.g. AF170575.2) beyond the FLAN influenza C reference sequences. VADR uses longer influenza C RefSeq sequences of which the FLAN references are subsequences (see the Materials and methods section), which result in zero VADR extrant5 or extrant3 errors for these 429 sequences. The other 14 sequences fail FLAN due to probable mutation at end errors which upon manual inspection appear to be invalid errors as the sequences all clearly end prior to the end of the CDS the error is reported for (e.g. the CM2 CDS for D78423.1).
Error comparison
Table 1 lists all FLAN errors, corresponding VADR alerts and error messages and counts in the combined training and testing sets. FLAN reports 1297 of these errors, and VADR reports 1008 of its analogs of those errors. Of these, 642 are consistent in that the same error is reported for the same feature (CDS or mature peptide), but 655 FLAN errors and 366 VADR errors are unique (not consistent). The majority of these unique error instances were examined and listed in our analysis of the sequences with different pass/fail outcomes described earlier. For example, at least 429 of the 655 unique FLAN errors were influenza C sequences that failed due to extra nucleotides upstream or downstream of the 5’ and/or 3’ ends (“at least” because one sequence could have both errors).
Classification and annotation comparison
Of the 58 555 total sequences in our training and testing sets, FLAN and VADR classify all but three to the same type, segment and subtype (for type A segments 4 and 6). FN395357.1, AM922160.1 and ON527769.1 are classified by FLAN as H2, H4 and H16 subtypes, respectively, but as H1, H10 and H1 by VADR. In all three cases, the top “blastn” hits against ‘nr’ support the VADR classification.
There are 196 683 total features annotated in our training and testing sets by one or both programs. Of these, both programs give identical start and stop coordinates for 194 119 (98.7%). There are 1331 (0.7%) features annotated by both programs but with different coordinates, 827 (0.4%) features that VADR annotates that FLAN does not and 406 (0.2%) features that FLAN annotates that VADR does not.
Taken together, these data demonstrate that VADR, when employing models derived mainly from FLAN’s reference nucleotide and protein sequences, largely reproduces FLAN’s pass/fail, classification and annotation results. The majority of problems detected by either program are detected by both, and analogous alerts or errors are reported. When the two programs differ, VADR nearly always provides the more appropriate pass/fail decision.
Efficacy of the novel VADR models
As noted earlier, the VADR influenza model set (v1.6.3-2) contains 17 additional influenza A, seven additional influenza D and five alternative influenza C models that are not derived from FLAN reference sequences. While there are very few INSDC sequences that match best to the 17 additional influenza A models based on novel H and N subtypes at the time of writing, using these additional models does improve VADR performance on those few sequences.
We used VADR to annotate all 977 136 influenza A sequences listed in NCBI virus on 13 December 2023 and found that only 78 match best to one of the 17 added models for H17/N10, H18/N11 or H19 subtypes. Of these, 57 were classified to models that matched their annotation in GenBank (e.g. KR077935.1 matched best to the CY125948.1 model and is annotated in GenBank as subtype H18/N11). All 57 of these passed, and only 13 would have passed if the 17 new models were not added. For the other 21 sequences, VADR almost certainly misclassified them to the new subtypes, in many cases probably due to their short length which can make classification more challenging (19 of the 21 are 90 nt or shorter). However, only four of these 21 failed VADR, and this is the identical set of four that would fail if run against the set of models without the new models. The new influenza C models also improve performance. As mentioned earlier, using the five new longer influenza C RefSeq models instead of models based on the non-RefSeq FLAN reference sequences allows 429 sequences in our training and testing sets to pass VADR that fail FLAN due to extra nucleotides upstream or downstream of the consensus end sequence.
Limitations and future directions
VADR is designed to be a general tool capable of validating and annotating most viruses with genomes less than about 30 kb. While building models using the “v-build.pl” module is straightforward, we have found that significant testing and manual modification of viral models are often necessary to achieve the level of accuracy and reliability necessary to use them in an automated fashion, such as in the context of automatically screening incoming GenBank sequence submissions. Our experience with influenza reinforces this as we were able to significantly improve performance of the initial models built from only the FLAN nucleotide reference sequences by adding additional proteins to our blastx libraries (mostly from FLAN’s set, see Table 4, “FLAN-nt” vs “final” rows). The preexistence of FLAN’s reference protein sets made this task much easier than it would have been otherwise. This required testing and model improvement are currently a major bottleneck in creating sufficiently accurate VADR models.
The relatively slow speed of VADR in annotating sequences can be limiting in some contexts. VADR is especially slow for longer sequences due to the high complexity of its search and alignment algorithms although this can be alleviated for viruses with relatively low sequence variability (e.g. SARS-CoV-2 (18)). For influenza sequences, which are nearly always less than 2500 nt, speed is less of an issue, especially for typical input data sets of less than 1000 sequences. When parallelized across 16 processors (using the –split—cpu 16 options), “v-annotate.pl” processed all 977 136 influenza A sequences in INSDC (listed in the NCBI virus resource on 13 December 2023) in just under 24 h on 2.2 GHz Intel Xeon processors. This averages to about 2500 sequences per processor per hour or about 1.5 s per sequence per processor. This speed is in the same ballpark as FLAN, which took about 14 min to annotate 1000 influenza A sequences from our training set in our hands or about 0.85 s per sequence, making it about twice as fast as single-processor VADR. Our recommended usage of “v-annotate.pl”, detailed in the documentation included with the influenza models, employs four processors, which ends up making VADR about twice as fast as FLAN in practice.
An important feature of FLAN is its ability to detect frameshifts using the ProSplign DNA to protein alignment software. ProSplign computes alignments at the protein level, by translating the input sequence and aligning it to reference proteins. VADR also attempts to detects frameshifts but does so at the nucleotide level, aligning the input nucleotide sequence to a reference genome sequence. In principle, when comparing sequences, working in protein space is more powerful due to the larger alphabet and higher information content of protein sequences (20). However, our testing of influenza annotation suggests that this distinction does not confer a large advantage to FLAN. We examined all the sequences that fail due to frameshifts in FLAN but not VADR, and in each case the frameshift call looked incorrect. Working in nucleotide space actually seems to allow VADR to detect potential short frameshifts that FLAN does not report. An example is shown in Figure 2.
Using VADR should enable simple model changes in the future. As novel influenza diversity is observed in INSDC sequence data, the VADR development team will work together with the NCBI Virus team to identify reference sequences for novel proteins or subtypes and use them to update the VADR models. While in principle FLAN models are also expandable in this way, in practice new reference sequences and proteins were rarely added.
Conclusions
The amount of viral sequence data generated by independent research and public health laboratories and submitted to public sequence databases will likely continue to grow. This underscores the need for publicly available tools that can be easily maintained and updated as new sequence diversity is encountered. The VADR package is a general tool that allows the validation and annotation of different types of viruses including several flaviviruses, caliciviruses, coronaviruses and now influenza (Orthomyxoviridae) using a single codebase. Since 2007, GenBank has used the FLAN software to validate and annotate incoming influenza sequences. Using models derived from the reference sequences used by FLAN, VADR gives very comparable annotation to FLAN on influenza A, B and C sequences and additionally allows annotation of influenza D sequences. When there are discrepancies, VADR usually gives more accurate annotation. VADR is freely available for users to download, install and run on Linux and Mac/OSX systems (https://github.com/ncbi/vadr). Based on our findings, we intend to start using VADR instead of FLAN for GenBank influenza sequence processing and to develop a VADR webserver.
Acknowledgement
We thank the NCBI systems team, especially Ron Patterson, for management of the compute farm.
Supplementary data
Supplementary data is available at Database online.
Conflict of interest
As a funding body, the NLM had no role in the design of the study; the collection, analysis, and interpretation of the data; and writing the manuscript.
Funding
This research was supported by the National Center for Biotechnology Information at the National Library of Medicine at the National Institutes of Health.
Data availability
VADR and the influenza models are in the public domain and are freely available at https://github.com/ncbi/vadr and https://bitbucket.org/nawrockie/vadr-models-flu. VADR depends on the following software, which is downloaded and installed as part of VADR installation: Bio-Easel v0.16, BLAST+ v2.15.0, Infernal v1.1.5, FASTA v36.3.8h, minimap v2.26 and Sequip v0.10. All data generated or analyzed during this study are included in this published article, its supplementary material or NCBI’s GenBank database. The VADR influenza models dataset (vadr-models-flu-1.6-2.tar.gz) includes information on mapping the FLAN reference sequences to INSDC sequences. Instructions for using VADR for influenza annotation can be found at https://github.com/ncbi/vadr/wiki/influenza-annotation. The supplementary material includes information on the the collection and analysis of the training and testing datasets as well as instructions for reproducing the tables in the paper (https://github.com/nawrockie/vadr-flu-paper-supplementary-material).

{kind=link}
{kind=link}